
【今回の主な内容】畳み込みニューラルネットワーク(CNN)の構築と応用
今回のテーマでは、画像認識タスクの土台となる、畳み込みニューラルネットワーク(CNN)の構築とその応用に焦点を当てます。CNNは、画像から特徴を抽出し、分類するために最適化されたモデル構造であり、その成功はディープラーニングの普及を加速させました。
本記事では、畳み込みニューラルネットワーク(CNN)の基本構造を理解し、PyTorchを用いて画像分類タスクを実践します。さらに、バッチ正規化やドロップアウトでモデルの安定性と汎化性能を向上させ、転移学習を活用して少量データで高精度な分類を実現します。Grad-CAMを使った解釈性の向上や、トレーニング済みモデルの保存・再利用手法も学び、実践的なスキルを習得します。
今回の学習目標
画像認識タスクにおける効率的なモデル構築と応用力を高めるために、畳み込みニューラルネットワーク(CNN)の理論と実践を深く理解し、実世界の課題解決に応用できるスキルを習得します。以下のポイントを柱に、基礎から応用までを体系的に学びます。
- CNNの基本構造と動作原理を理解する
- 畳み込み層、プーリング層、全結合層の役割と機能を明確に理解します。
- 数式を用いてフィルタ操作や特徴マップの生成過程を解説します。
- 視覚的な図を用いて概念を具体的に把握します。
- 画像分類モデルの論文を読みます。
- バッチ正規化とドロップアウトを組み合わせて、拡張CNN(Dilated Convolution)モデルを構築してみる。
- 転移学習を用いた効率的な学習を体験する
- 事前学習済みモデルを用いることで、少量データでの高精度な分類を実現します。
- 転移学習が実際のプロジェクトでどのように役立つかを具体的なコード例で学びます。
- モデルの解釈性を向上させる
- Grad-CAMを用いて、モデルがどのように決定を下したかを可視化します。
- ヒートマップを通じて、モデルの信頼性や解釈性を高めます。
- モデルの保存と再利用を習得する
- トレーニング済みモデルを保存し、再利用するための実践的な方法を学びます。
- 将来のプロジェクトで使用するための効率的なモデル管理方法を習得します。
- CNNの応用例
- 様々なCNNの派生モデルを用いてCNNの応用例を探ります。
ゴール
- 実用的なCNN構築力
CNNの構造を理解し、基礎的な画像分類タスクを解決する力を養います。 - モデル性能の向上
正則化や転移学習を活用し、より高精度なモデルを設計します。 - 解釈性と再利用性の確保
Grad-CAMを通じたモデルの解釈性向上や、効率的なモデル保存・再利用の技術を習得します。 - 応用力の強化
得られたスキルを基に、次回以降の高度な深層学習技術(RNNやNLPなど)への応用準備を整えます。
第9回(前編・中編)の振り返り
前回の中編では、ディープラーニングモデルの効率化と汎化性能向上の手法を学びました。具体的には、ミニバッチ学習による計算効率化とバッチ正規化による学習安定性の向上、SGDやAdamなどの最適化アルゴリズムの特徴と学習率設定、データ拡張やL1/L2正則化、ドロップアウトによる過学習防止、さらに、知識蒸留や枝刈りによるモデルの軽量化と推論速度向上について取り上げました。これらの手法を組み合わせることで、モデルの性能向上と効率的な学習プロセスの構築が可能となります。
さらに、前編ではディープラーニングの基本構造や、損失関数と活性化関数の役割について学びました。
ミニバッチ学習を使ったニューラルネットワークの動作イメージ
これらの基礎知識を踏まえ、今回の後編では、畳み込みニューラルネットワーク(CNN)の基本構造と動作原理、PyTorchを用いたCNNモデルの実装、バッチ正規化とドロップアウトの効果、転移学習、モデルの解釈性向上、モデルの保存と再利用について詳しく解説していきます。
CNNの基本構造と動作原理
この章では、画像認識で広く使われている畳み込みニューラルネットワーク(Convolutional Neural Network:CNN)の基本構造と動作原理を解説します。CNNは画像認識や特徴を抽出することにおいてディープラーニングで重宝されているアルゴリズムです。金融時系列データなども扱えるので幅広く利用されていると言えます。この章では数式やコーディング例、図解を用いて、CNN内部の処理を具体的に説明していきます。
画像認識とは?
画像データを入力として、その画像の特徴を解析する技術
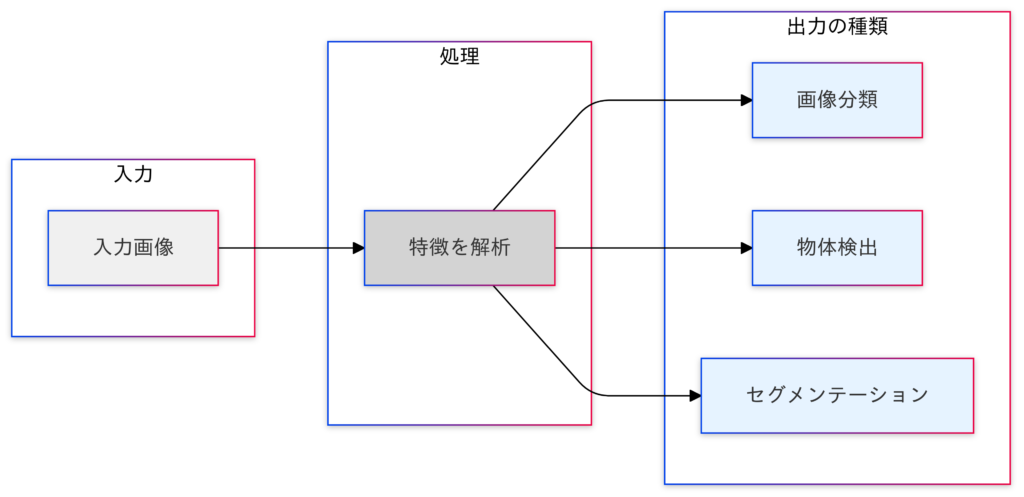

画像データの形状について
画像データは縦と横のピクセルで構成され、カラー画像の場合、各ピクセルにはRGB(赤、緑、青)の3つのチャンネルの値が含まれます。このため、画像データは「縦 × 横 × チャンネル数(通常3:カラー画像)」という3次元の形状を持ちます。この3次元構造により、近接するピクセル間の空間的な関連性や、RGB間の密接な関係を活用してパターンや特徴を抽出できます。モノクロ画像の場合は、チャンネル数が1になるため、「128×128×1」となります。
# RGBチャネルを分離
red_channel = image.copy()
red_channel[:, :, 1] = 0 # 緑チャネルをゼロに
red_channel[:, :, 2] = 0 # 青チャネルをゼロに
green_channel = image.copy()
green_channel[:, :, 0] = 0 # 赤チャネルをゼロに
green_channel[:, :, 2] = 0 # 青チャネルをゼロに
blue_channel = image.copy()
blue_channel[:, :, 0] = 0 # 赤チャネルをゼロに
blue_channel[:, :, 1] = 0 # 緑チャネルをゼロに
# モノクロ(グレースケール)画像を生成
gray_image = color.rgb2gray(image)
全結合層の問題点とCNNの有用性
CNNの目的:
- CNNの主な目的は、画像データからその特徴を自動的に抽出し、高精度な認識・分類を行うことです。人間が手作業で特徴を設計するのではなく、大量のデータから自動的に学習することで、複雑な画像パターンを認識できるようになります。
| 項目 | 全結合層の問題点 | CNNの有用性 |
|---|---|---|
| データ構造 | 画像データを1次元データに変換するため、3次元構造が無視される | 入力から出力まで3次元構造を保持 |
| 空間的特徴 | 近接ピクセル間の空間的関係が失われる | 空間的関係やパターンを保ちながら特徴を学習 |
| 計算効率 | パラメータ数が多く計算コストが高い | フィルタ共有によりパラメータ数を削減し効率的に計算 |
| 位置不変性 | 位置に依存し、特徴の認識が困難 | プーリング層により位置不変性を獲得 |
| 学習する特徴 | エッジや局所的なパターンなどの特徴を効率的に学習できない | 深層構造で単純なパターンから複雑な特徴まで学習可能 |
画像データにおける移動不変性とは?
物体が画像内で異なる位置にあっても、同じように認識できる性質のことを指します。これは特に画像認識において重要な概念です。
例えば、猫の画像が中央にある場合でも、左上や右下に移動している場合でも、同じ「猫」として正しく分類できることが求められます。
畳み込み層とプーリング層の役割
私たちの脳の視覚野にある単純型細胞は、局所的な特徴(例: 縦線)を検出しますが、特徴の位置がずれると別の特徴として認識してしまいます。一方、複雑型細胞は同じ特徴が受容野内で位置を変えても同じ特徴として扱うことができ、移動不変性を実現します。この仕組みを模倣したのが畳み込み層とプーリング層で、畳み込み層が局所的な特徴を検出し、プーリング層が特徴の位置の変化に影響されない認識を可能にしています。
CNNの適用例:
CNNの適用例は画像認識の分野以外にも金融や時系列データ分野などの他の分野にも活用することができます。
- 画像認識分野
| 分野 | 用途 | 具体例 |
|---|---|---|
| 物体認識 | 物体を分類し、自動運転やセキュリティシステムに活用 | 犬、猫、車などの認識 |
| 物体検出 | 画像内の特定物体の位置を特定 | 歩行者検出、自動運転 |
| 画像セグメンテーション | ピクセルレベルで領域を分類 | 医療画像での腫瘍部位の検出 |
| 顔認識 | 個人認証や写真整理アプリに利用 | 顔画像を基に個人を特定 |
| 画像キャプション生成 | 画像の内容を説明する文章を生成 | 視覚障碍者向けの画像説明生成 |
| 医用画像診断 | CTやX線での病変部位の検出 | 腫瘍や病変の検出 |
| 異常検知 | 工場製品やシステムの異常を検知 | 製造ラインの欠陥検知 |
| 画像生成 | GANを活用して新しい画像を生成 | 新しい写真やアートの生成 |
- 金融や時系列データ分野
| 分野 | 用途 | 具体例 |
|---|---|---|
| 時系列データの特徴抽出 | 時間の経過に伴うパターンを学習 | 畳み込み層でトレンドや周期性を捉える |
| 株価予測 | 株価データの短期的な特徴を抽出し予測モデルを構築 | 株式市場での価格変動の予測 |
| 異常検知 | 不正取引や市場変動の異常を検知 | クレジットカードの不正取引検出 |
| 経済データ分析 | 経済指標間の関連性を学習しトレンドを予測 | GDPや金利、インフレ率の関係性の分析 |
| ポートフォリオ最適化 | 資産データでリスクとリターンを最適化 | 複数の資産を組み合わせたポートフォリオ設計 |
| アルゴリズム取引 | 価格変動や取引量の特徴を学習し取引戦略を策定 | 高頻度取引での売買タイミングの決定 |
| 信用スコアリング | 顧客の履歴を基に信用リスクを評価 | 個人や企業の信用スコア計算 |
- 他のデータドメイン
| 分野 | 用途 | 具体例 |
|---|---|---|
| 自然言語処理(NLP) | 単語や文章を画像のように扱い、特徴を抽出 | 文書分類、感情分析、テキストデータのCNN分析 |
| センサーデータ解析 | IoTセンサーのデータを基に異常検知や予測 | 設備の異常検知、メンテナンス時期の予測 |
| バイオインフォマティクス | DNAやタンパク質配列を解析し疾患関連性を特定 | 遺伝子解析、疾患予測 |
| 音声認識 | 音声波形をCNNで処理しキーワード検出や音声分類 | 音声アシスタント、コマンド認識 |
CNNの3大要素:畳み込み層、プーリング層、全結合層
CNNは、主に畳み込み層(Convolutional Layer)、プーリング層(Pooling Layer)、全結合層(Fully Connected Layer) の3つの要素から構成されます。
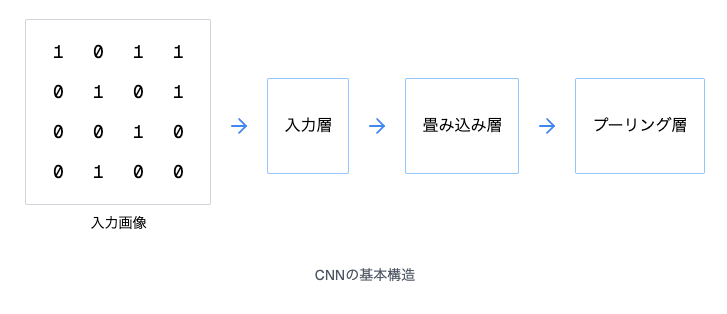
畳み込み層
畳み込み層は、CNNの中核を担う要素であり、フィルタ(カーネル) を用いた畳み込み演算によって、入力画像から特徴マップ(Feature Map) を生成します。
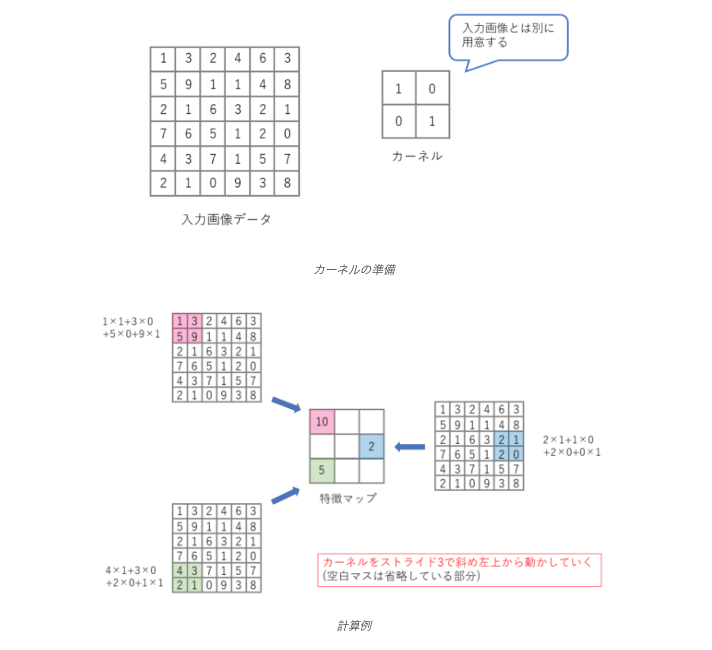
フィルタ操作の詳細(上図参照)
- フィルタの適用
- 入力画像データに対して、フィルタを一定のストライド幅でスライドさせながら、フィルタと重なった領域の画素値との間で要素積の和(内積) を計算します。
- バイアスの加算
- 内積の結果にバイアス項を加算します。
- 活性化関数の適用
- バイアス加算後の値に活性化関数(ReLUなど) を適用し、非線形性を導入します。
- 特徴マップの生成
- 上記の計算結果が、出力される特徴マップの対応する位置の画素値となります。
数式による演算の表現:
- 入力画像を $I$、フィルタを$F$、出力される特徴マップを$M$とすると、特徴マップの各要素$M_{i,j}$は以下のように計算されます。
$$M_{i,j} = \sigma \left( \sum_{m=0}^{K-1} \sum_{n=0}^{K-1} F_{m,n} \cdot I_{i \cdot S + m, j \cdot S + n} + b \right)$$
- $K$:フィルタのサイズ($K × K$)
- $S$:ストライド
- $b$:バイアス項
- $α$:活性化関数(例:ReLU)
上の図の場合
6×6の入力画像に対して、2×2のフィルタをストライド1で適用する場合、フィルタは左上から右下へ1ピクセルずつ移動しながら、各位置で内積計算とバイアス加算、活性化関数の適用が行われます。その結果、3×3の特徴マップが出力されます。
複数フィルタによる多次元特徴マップ
通常、畳み込み層では複数のフィルタを使用します。各フィルタは異なる特徴(エッジ、テクスチャなど)を捉えるように学習され、それぞれが異なる特徴マップを出力します。その結果、出力される特徴マップは、フィルタの数と同じチャネル数を持つ多次元のデータとなります。
パディング
入力画像の端の部分でフィルタがはみ出してしまう場合、画像の周囲に値を埋めるパディングを行います。パディングを行うことで、出力される特徴マップのサイズを調整したり、端の情報が失われるのを防いだりすることができます。
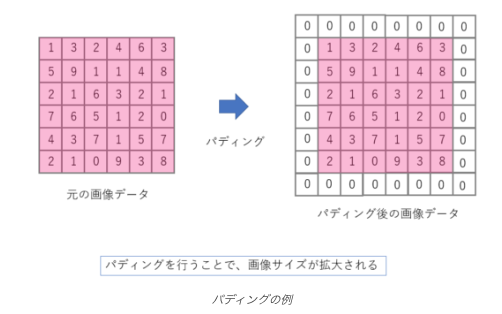
https://zero2one.jp/learningblog/cnn-for-beginners/
畳み込み層のコード例:
import torch
import torch.nn as nn
# 畳み込み層の定義
conv_layer = nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, stride=1, padding=1)
# 入力データ(例:28x28のグレースケール画像)
input_data = torch.randn(1, 1, 28, 28)
# 畳み込み層の適用
output_data = conv_layer(input_data)
# 出力データのサイズ確認
print(output_data.shape) # 出力: torch.Size([1, 32, 28, 28]) (バッチサイズ, チャネル数, 高さ, 幅)この例では、入力チャネル数1(グレースケール)、出力チャネル数32、カーネルサイズ3×3、ストライド1、パディング1の畳み込み層を定義しています。入力データとして、28×28のグレースケール画像を模したランダムなテンソルを使用しています。nn.Conv2dによってフィルタ操作が行われ、32チャネルの28×28の特徴マップが出力されます。
出力サイズの計算:畳み込み層の出力サイズは次の数式で計算できます。
$$W_{\text{out}} = \frac{W_{\text{in}} – K + 2P}{S} + 1$$
$$H_{\text{out}} = \frac{H_{\text{in}} – K + 2P}{S} + 1$$
- $W_{out},H_{out}$:出力の幅と高さ
- $W_{in},H_{in}$: 入力の幅と高さ
- $K$:フィルタ(カーネル)のサイズ
- $P$:パディングの数
- $S$:ストライド(フィルタをスライドさせる幅)
畳み込み層のコード例の場合:
$$W_{\text{out}} = \frac{28 – 3 + 2(1)}{1} + 1 = \frac{28 – 3 + 2}{1} + 1 = 28$$
$$H_{\text{out}} = \frac{28 – 3 + 2(1)}{1} + 1 = 28$$
- 出力サイズ:28×28
プーリング層
プーリング層は、特徴マップを小さな領域に分割し、各領域の代表値(最大値や平均値)を抽出することで、情報の集約と次元削減を行います。これにより、位置不変性の向上、計算コストの削減、過学習の抑制などの効果が得られます。
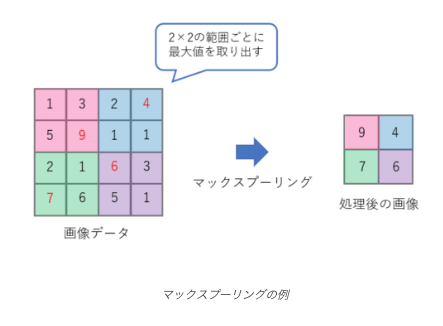
https://zero2one.jp/learningblog/cnn-for-beginners/
主なプーリングの種類
- 最大プーリング(Max Pooling):
- 領域内の最大値を代表値として抽出します。エッジなどの強い特徴を強調する効果があります。
- 平均プーリング(Average Pooling):
- 領域内の平均値を代表値として抽出します。特徴マップ全体の情報を保持しつつ、ノイズの影響を軽減する効果があります。
数式による演算の表現:
- 例えば、2×2の領域で最大プーリングを行う場合、特徴マップの各要素$M_{i,j}$は以下のように計算されます。
$$M_{i,j} = \max(M_{2i,2j}, M_{2i+1,2j}, M_{2i,2j+1}, M_{2i+1,2j+1})$$
プーリング層のコード例:
import torch
import torch.nn as nn
# 最大プーリング層の定義
max_pool_layer = nn.MaxPool2d(kernel_size=2, stride=2)
# 入力データ(例:28x28の特徴マップ)
input_data = torch.randn(1, 32, 28, 28)
# プーリング層の適用
output_data = max_pool_layer(input_data)
# 出力データのサイズ確認
print(output_data.shape) # 出力: torch.Size([1, 32, 14, 14]) (バッチサイズ, チャネル数, 高さ, 幅)この例では、カーネルサイズ2×2、ストライド2の最大プーリング層を定義しています。入力データとして、32チャネルの28×28の特徴マップを模したランダムなテンソルを使用しています。nn.MaxPool2dによってプーリング操作が行われ、32チャネルの14×14の特徴マップが出力されます。
出力サイズの計算:プーリング層も畳み込み層と同様に計算します。
$$W_{\text{out}} = \frac{W_{\text{in}} – K}{S} + 1$$
$$H_{\text{out}} = \frac{H_{\text{in}} – K}{S} + 1$$
- パディング ($P$) が無い場合の計算です。
- プーリング層では通常、ストライドとカーネルサイズは同じ値を取ることが多いです。
プーリング層のコード例の場合:
$$W_{\text{out}} = \frac{28 – 2 + 2(0)}{2} + 1 = \frac{28 – 2}{2} + 1 = 14$$
$$H_{\text{out}} = \frac{28 – 2 + 2(0)}{2} + 1 = 14$$
- 出力サイズ:14×14
全結合層の役割
畳み込み層とプーリング層で抽出・集約された特徴は、最終的に全結合層(Fully Connected Layer) に入力されます。全結合層は、従来のニューラルネットワークと同様の構造であり、各ニューロンが前の層の全てのニューロンと結合しています。
全結合層の役割
- 特徴の統合:
- 畳み込み層とプーリング層で抽出された局所的な特徴を統合し、画像全体を表現する特徴ベクトルを生成します。
- 分類・回帰
- 生成された特徴ベクトルを基に、最終的な出力(クラスラベル、回帰値など)を計算します。
平坦化 (Flatten):
- 全結合層に入力する前に、多次元の特徴マップを1次元のベクトルに変換する必要があります。この処理を平坦化(Flatten) と呼びます。
出力層:
- 出力層には、タスクに応じた活性化関数が用いられます。
- 分類問題:Softmax関数を用いて、各クラスに属する確率を出力します。
- 回帰問題:恒等関数などを用いて、連続値を出力します。
数式による表現:
全結合層の出力$y$は、入力ベクトルを$x$、重み行列を$W$、バイアスベクトルを$b$とすると、以下のように計算されます。
$$y = \sigma(Wx + b)$$
- $α$は活性化関数(例:Softmax)です。
全結合層のコード例:
import torch
import torch.nn as nn
# 全結合層の定義
fc_layer = nn.Linear(in_features=14*14*32, out_features=10) # 例:入力サイズ14x14x32、出力サイズ10
# 入力データ(例:平坦化された特徴マップ)
input_data = torch.randn(1, 14*14*32)
# 全結合層の適用
output_data = fc_layer(input_data)
# 出力データのサイズ確認
print(output_data.shape) # 出力: torch.Size([1, 10]) (バッチサイズ, 出力サイズ)この例では、入力サイズ14x14x32(平坦化された特徴マップを想定)、出力サイズ10(例:10クラス分類)の全結合層を定義しています。nn.Linearによって全結合層の演算が行われ、サイズ10の出力ベクトルが得られます。
CNNの全体構造

- 入力画像: CNNに入力される画像データ。
- 畳み込み層: フィルタを用いて特徴マップを抽出。
- 活性化関数: 非線形性を導入(例:ReLU)。
- プーリング層: 特徴マップをダウンサンプリングし、情報の集約と次元削減。
- 平坦化: 多次元の特徴マップを1次元ベクトルに変換。
- 全結合層: 特徴を統合し、最終的な出力(例:各クラスの確率)を計算。
- 出力: ネットワークの予測結果(例:最も確率の高いクラス)。
この流れを複数回繰り返すことで、より複雑な特徴を捉えることが可能になります。
受容野の拡大:
出力層のニューロンが影響を受ける入力データの範囲。畳み込み層やプーリング層を重ねることで、受容野は広がっていき、より大局的な特徴を捉えることができるようになります。
パラメータの共有:
畳み込み層では、同じフィルタを画像全体に適用するため、パラメータが共有されます。これにより、パラメータ数を大幅に削減し、学習の効率化と過学習の抑制を実現しています。
im2col関数の理解
im2col関数は、畳み込み演算を効率化するための技術で、入力画像を小さなパッチに分割し、それらを列に並べて行列の積として計算します。PyTorchの torch.nn.Conv2d などの関数は、この処理を内部的に最適化しており、手動で実装する必要はありません。ただし、im2colの仕組みを理解することで、畳み込みの計算原理やCNNの効率化について深く学ぶことができます。
https://qiita.com/MA-fn/items/45a45a7417dfb37a5248
PyTorchにおける組み込み関数でim2colを実装:
torch.nn.functional.unfoldを使用することで、im2colの動作を実現できます。これにより、入力データを小さなパッチに分割し、それらを列として並べることができます。この操作は、標準的な畳み込み演算以外のカスタム操作を実装するための基盤となります。
具体的には、unfoldを使用して入力データを展開し、その後にカスタムフィルタリングや非線形変換を行うことができます。以下に、unfoldを使用してカスタム操作を実装する例を示します。
import torch
import torch.nn.functional as F
# 入力データの準備
input_data = torch.randn(1, 3, 5, 5) # (N, C, H, W)
# フィルタサイズ
filter_h = 3
filter_w = 3
# PyTorchのunfoldを使用してim2colを実現
unfold = F.unfold(input_data, kernel_size=(filter_h, filter_w), stride=1, padding=1)
print("Unfold result shape:", unfold.shape)
# カスタムフィルタリング操作(例:フィルタを適用して非線形変換を行う)
# ここでは単純なフィルタリング操作を行います
weight = torch.randn(2, 3, 3, 3) # (out_channels, in_channels, filter_h, filter_w)
weight_flat = weight.view(2, -1)
output_unfold = torch.matmul(weight_flat, unfold)
# バイアスを追加
bias = torch.randn(2)
output_unfold = output_unfold + bias.view(-1, 1)
# 出力を元の形状に戻す
output_h = (input_data.shape[2] + 2 * 1 - filter_h) // 1 + 1
output_w = (input_data.shape[3] + 2 * 1 - filter_w) // 1 + 1
output_unfold = output_unfold.view(1, 2, output_h, output_w)
print("Custom convolution result shape using unfold:", output_unfold.shape)
# PyTorchの畳み込み演算
conv_layer = torch.nn.Conv2d(in_channels=3, out_channels=2, kernel_size=3, stride=1, padding=1)
output = conv_layer(input_data)
print("PyTorch convolution result shape:", output.shape)
# 結果の比較
print("Difference between custom and PyTorch convolution:", torch.abs(output - output_unfold).sum().item())im2colを使用したカスタム操作は、標準的な畳み込みと異なる変換を行うため、特定のタスクやデータセットで精度向上が期待できる場合があります。ただし、効果はタスクやデータ特性に依存し、常に優れるわけではありません。標準的な手法との比較検証が重要で、通常はPyTorchの組み込み関数を使用するのが推奨されますが、特定のニーズに応じたカスタム操作も有効です。
- カスタム操作の利点:
- 特定のタスクやデータセットに対して、標準的な畳み込み演算よりも良い結果をもたらすことがあります。
- フィルタの設計や非線形変換をカスタマイズすることで、精度を向上させることができます。
CNNの理解を深めるための重要な論文(画像分類)
論文1:LeNet-5 (1998)
- Y. LeCun らによる初期のCNNモデル。手書き数字認識で高い性能を示し、CNNの有効性を実証。

論文2:AlexNet (2012)
- A. Krizhevsky らによる、ImageNet Large Scale Visual Recognition Challenge (ILSVRC) で優勝したモデル。ReLUの採用、GPUによる高速化、データ拡張など、現在のCNNの基礎となる技術を導入。
ImageNet Classification with Deep Convolutional Neural Networks
- CNNアーキテクチャの革新
- 本論文では、ReLU活性化関数、ローカル応答正規化、オーバーラッピングプーリングを導入した新しいCNNを提案。この設計により、画像認識の精度が飛躍的に向上しました。
- 大規模データセットとGPUの活用
- ImageNetデータセットとGPUを活用することで、計算効率を大幅に向上させました。これにより、高精度な分類モデルをわずか5〜6日で訓練可能とし、大規模モデルの実用化を現実のものにしました。
- 競争的な性能向上の実証
- ILSVRC-2012でトップ5エラー率を15.3%に削減し、従来手法を大きく上回る性能を実現しました。また、モデルが色や形状の特徴を効果的に学習していることを視覚的に確認しました。
論文3:VGGNet (2014)
- K. Simonyan らによる、深い層を持つCNNモデル。3×3の小さなフィルタを複数重ねることで、深いネットワークを効率的に学習できることを示した。

- 非常に深いConvNetアーキテクチャの提案
- 3×3フィルタを活用し、最大19層の非常に深いConvNetを設計しました。このアプローチにより、浅いネットワークを大きく上回る性能を達成し、ネットワークの深さが画像認識精度向上の鍵であることを明確に示しました。
- 大規模データセットでの性能向上
- ImageNetのILSVRC-2014でトップ5エラー率6.8%を達成し、当時の最先端性能を記録しました。また、Pascal VOCやCaltechなどの他のデータセットでも優れた汎化性能を示し、その有効性を実証しました。
- 幅広い応用可能性と影響
- 提案モデルはセマンティックセグメンテーションや物体検出などの多様なタスクにも適用可能で、その公開アーキテクチャは多くの研究に活用されています。この成果はディープラーニングの発展に大きく貢献しました。
論文4:ResNet (2015)
- K. He らによる、残差接続 (Residual Connection) を導入したモデル。非常に深いネットワークでも学習を安定化させ、精度を向上させることに成功。
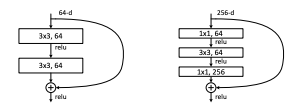
左:ResNet34の図3のような構成ブロック(56×56特徴マップ上)。右:ResNet-50/101/152の「ボトルネック」構成ブロック。
- 残差学習フレームワークの提案
- 深いネットワークの学習を容易にするため、残差関数を学習するResidual Learningを提案。ショートカット接続を導入することで、勾配消失や精度劣化問題を効果的に解消しました。
- ImageNetでの画期的な成果
- 最大152層のResNetでILSVRC 2015においてトップ5エラー率3.57%を達成。従来のモデルに比べ、高い精度を保ちながら計算コストを削減し、深層学習の限界を突破しました。
- 幅広い応用と汎化性能の向上
- 提案モデルは、ImageNet分類に留まらず、COCOやPascal VOCでの物体検出・セグメンテーションなど、多様なタスクにおいて性能を大幅に向上させることを実証しました。
ResNetのコーディング例:
import torch
import torch.nn as nn
from torchvision import models
# デバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
# 事前学習済みのResNetモデルのロード
model = models.resnet18(pretrained=True)
# 最終層の置き換え(CIFAR-10は10クラス)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 10)
# モデルをデバイスに移動
model = model.to(device)このコードを使用することで、ResNetを使った画像分類モデルを簡単に構築することができます。
論文5:GoogLeNet/Inception (2014)
- C. Szegedy らによる、Inceptionモジュールを用いたモデル。複数のサイズのフィルタを並列に適用し、計算効率と精度を両立。

- Inceptionアーキテクチャの提案
- 1×1, 3×3, 5×5の畳み込みとプーリングを並列に実行し、多スケール情報を統合するInceptionモジュールを提案。次元削減により計算効率を向上し、深いモデルの学習を実現しました。
- GoogLeNetの設計と成果
- 22層のGoogLeNetは、従来モデルより少ないパラメータ(1200万)で、ILSVRC 2014の分類タスクでトップ5エラー率6.67%を達成し、1位の性能を記録しました。
- 幅広い応用と高効率
- Inceptionアーキテクチャは、分類だけでなく検出タスク(mAP43.9%)でも最先端の性能を達成。パラメータ数を抑えつつ、高精度な結果を提供する柔軟性が他の分野への応用を可能にしました。
GoogLeNetのコーディング例:
import torch
import torch.nn as nn
from torchvision import models
# デバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
# 事前学習済みのGoogLeNet(Inception v3)モデルのロード
model = models.inception_v3(pretrained=True)
# 最終層の置き換え(CIFAR-10は10クラス)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 10)
# モデルをデバイスに移動
model = model.to(device)論文6:DenseNet(2016)
- DenseNetは、各層が全ての前層と直接接続される構造を持ち、特徴の再利用と勾配の伝播を促進します。これにより、パラメータ数を抑えつつ高い精度を実現し、効率的な学習が可能となりました。


- Dense Blockによる効率的な特徴再利用
- DenseNetは、各層をすべての前の層と直接接続するDense Blockを導入。これにより、特徴マップを効率よく再利用しながら、勾配消失を防ぎ、高い学習効率と性能を実現しました。
- 少ないパラメータで高い性能
- DenseNetは、特徴を結合して再利用する設計により、ResNetの約1/3のパラメータで同等以上の性能を達成。CIFARやImageNetで最先端の結果を記録し、モデルの効率性を大幅に向上させました。
- 汎用性の高い設計
- DenseNetのアーキテクチャは、画像分類だけでなく、物体検出やセグメンテーションなど多様なタスクに適用可能。その汎用性の高さから、他のネットワーク設計にも影響を与え、新たな研究の基盤となっています。
DenseNetのコーディング例:
import torch
import torch.nn as nn
from torchvision import models
# デバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
# 事前学習済みのDenseNetモデルのロード
model = models.densenet121(pretrained=True)
# 最終層の置き換え(CIFAR-10は10クラス)
num_ftrs = model.classifier.in_features
model.classifier = nn.Linear(num_ftrs, 10)
# モデルをデバイスに移動
model = model.to(device)論文7:Vision Transformers(ViT)
- ViTは、従来の畳み込みニューラルネットワーク(CNN)に代わり、トランスフォーマーアーキテクチャを画像分類に適用しました。画像をパッチに分割し、トークンとして処理することで、高精度な分類を実現しています。
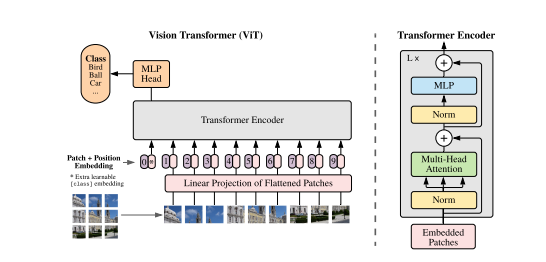
得られたベクトル列を標準的なTransformerエンコーダーに送る。分類を行うために、学習可能な「分類トークン」をシーケンスに追加するという標準的なアプローチを用いる。「分類トークン “をシーケンスに追加する。Transformerエンコーダの図は、以下から着想を得た。論文より抜粋

- Transformerを直接画像に適用
- Vision Transformerは、画像をパッチに分割し、それをTransformerに直接入力するアプローチを提案。従来のCNNに依存せず、Transformerを画像認識タスクに効果的に活用しました。
- 大規模データセットによる性能向上
- 14M~300M画像の大規模データセットで事前学習することで、従来のResNetやEfficientNetと同等以上の性能を達成。特にImageNetで88.55%の精度を記録しました。
- 計算効率の向上
- CNNよりも少ない計算資源で学習可能で、ImageNetやCIFAR-100など幅広いデータセットで優れた結果を示しました。特に学習時間の短縮とメモリ効率が特徴です。
ViTのコーディング例:
import torch
from transformers import ViTForImageClassification, ViTFeatureExtractor
# デバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
# データの前処理
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224-in21k')
# 事前学習済みのViTモデルのロード
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224-in21k', num_labels=10)
# モデルをデバイスに移動
model = model.to(device)Dilated Convolution(拡張畳み込みモデル)
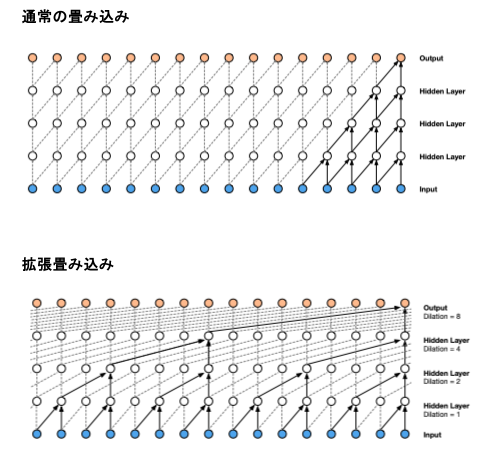
拡張畳み込みモデル は、通常の畳み込みに「間隔(dilation rate)」を導入したもので、フィルタの受容野を拡大しながらパラメータ数を増加させず、計算コストを抑えた形で特徴を抽出できる手法です。
- 通常の畳み込み:フィルタが連続する画素に適用される。
- 拡張畳み込み:フィルタが間隔を置いた画素に適用され、広範囲の特徴を取得。
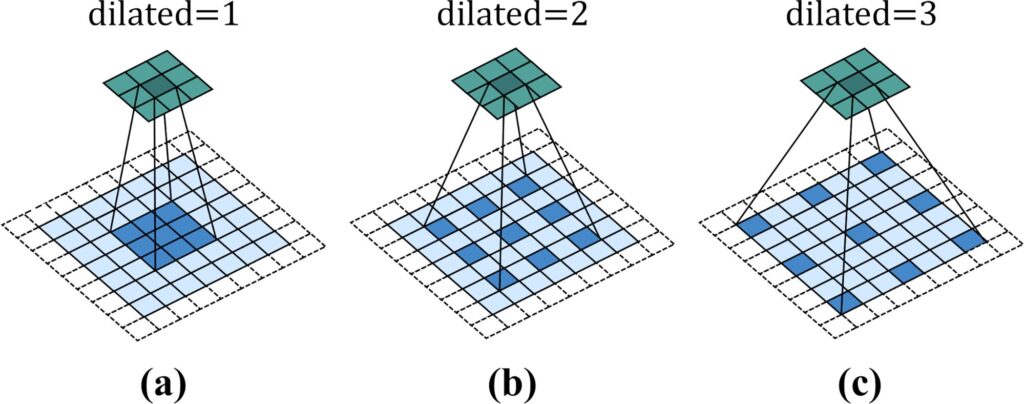
数式:
- 通常の畳み込みの出力
$$y[i] = \sum_k x[i + k] \cdot w[k]$$
- 拡張畳み込みの出力(間隔 $r$ を導入)
$$y[i] = \sum_k x[i + r \cdot k] \cdot w[k]$$
$x$:入力テンソル、$y$:出力テンソル、$w$:フィルタの重み、$k$:フィルタ内の画素位置、$r$: 拡張率(dilation rate)
- フィルタサイズが $K$ で拡張率が $r$ の場合、有効なフィルタサイズ(受容野の大きさ)は $K_{\text{effective}} = K + (K – 1) \cdot (r – 1)$ となります。
目的と課題
目的:
- 広範囲の特徴抽出
- 入力データ全体の文脈を捉えたい場合に有効(例:セマンティックセグメンテーション)。
- 計算効率の向上
- パラメータ数や計算コストを増やさず、受容野を拡大。
- 多解像度情報の取得
- 拡張率を変化させて異なるスケールの特徴を同時に学習可能。
課題:
- グリッド効果
- 拡張率が大きくなると、画素間に未使用の「穴」が増え、情報を取りこぼす可能性がある。
- 局所特徴の損失
- 広範囲の情報を取得する一方で、局所的な特徴の解像度が低下する。
適用例:
| 適用例 | 詳細 | 具体例 |
|---|---|---|
| セマンティックセグメンテーション | 画像全体の文脈情報を捉えながら、ピクセルレベルのラベルを予測。 | DeepLab |
| 時系列データ | 遠方の時間ステップの特徴を捉えつつ、短期的なパターンも保持。 | 音声生成モデル:WaveNet |
| 医用画像解析 | 広範囲の組織構造を捉えつつ、細部の特徴を保持。 | 医用画像解析(特定のモデル名なし) |
拡張畳み込みモデルにおけるバッチ正規化とドロップアウトの有効性
拡張畳み込みは、広範囲の特徴を効率的に抽出できる手法ですが、その効果を最大化するためには学習の安定性や汎化性能を高める工夫が重要です。ここで役立つのがバッチ正規化 と ドロップアウトの活用です。
バッチ正規化の有効性
バッチ正規化とは?
前回の【第9回】ディープラーニングの基礎とCNNの仕組み(中編)で学びましたので、復習がてら参考にしてみて下さい。バッチ正規化はそれぞれのデータセットや分析の仕方に応じた選び方ができるので工夫のしがいがあるのかも知れません。

課題の背景
- 拡張畳み込みでは、広範囲の特徴を捉えるために受容野が大きくなります。この場合、モデルの深層部分で勾配消失や爆発が発生しやすく、学習の収束が遅れることがあります。
| 効果 | 詳細 |
|---|---|
| 勾配消失・爆発の緩和 | 各層への入力を正規化することで、勾配が安定し、モデル全体の学習がスムーズになる。 |
| 学習速度の向上 | 入力値のスケールを揃えることで、最適化アルゴリズムが効率的に動作し、学習が加速する。 |
| 表現力の保持 | スケールとシフトのパラメータにより、ネットワークの表現力を損なわずに正規化を行える。 |
拡張CNNでの利点
- 拡張畳み込みでは広範囲の情報を扱うため、特徴マップのスケールが層ごとに大きく変化しやすいですが、バッチ正規化を適用することで、これらの変化を抑制し、安定した学習を実現します。
適用箇所
- 主に拡張畳み込み層や全結合層の直後に適用。
ドロップアウトの有効性
ドロップアウトとは?
こちらも前回の【第9回】ディープラーニングの基礎とCNNの仕組み(中編)で学びましたので、復習がてら参考にしてみて下さい。 ドロップアウトもそれぞれのデータセットや分析の仕方に応じた選び方ができるので工夫のしがいがあるのかも知れません。
課題の背景
- 拡張畳み込みモデルでは、広範囲の情報を捉える一方で、モデルが特定の特徴やニューロンに過度に依存する過学習が発生しやすくなります。
以下のようにドロップアウトの効果をテーブルにまとめました:
| 効果 | 詳細 |
|---|---|
| 過学習の防止 | ニューロンをランダムに無効化することで、ネットワークがより汎化性能の高い特徴を学習する。 |
| モデルの頑健性向上 | 複数のサブネットワークを学習するような効果を持ち、予測がより頑健になる。 |
拡張CNNでの利点
拡張畳み込みでは広範囲の特徴が重要視されますが、局所的な特徴やノイズにモデルが依存しすぎると汎化性能が低下します。ドロップアウトを導入することで、ノイズや特定のパターンへの依存を抑え、より広範囲の特徴を安定して学習できます。
適用箇所
- 全結合層や浅い層に適用して汎化性能を向上。
バッチ正規化とドロップアウトの併用した拡張畳み込みモデルの実装例:
ライブラリのインポート
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torchvision import datasetsデバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")データの前処理
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])- 画像を32×32にリサイズし、テンソルに変換し、正規化します。
データセットの準備
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=32, shuffle=False)拡張CNNモデルの定義
class DilatedCNN(nn.Module):
def __init__(self):
super(DilatedCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, padding=1, dilation=1)
self.bn1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=2, dilation=2)
self.bn2 = nn.BatchNorm2d(64)
self.conv3 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=4, dilation=4)
self.bn3 = nn.BatchNorm2d(128)
self.fc1 = nn.Linear(128 * 4 * 4, 256)
self.dropout = nn.Dropout(0.5)
self.fc2 = nn.Linear(256, 10)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, x):
x = self.pool(F.relu(self.bn1(self.conv1(x))))
x = self.pool(F.relu(self.bn2(self.conv2(x))))
x = self.pool(F.relu(self.bn3(self.conv3(x))))
x = x.view(-1, 128 * 4 * 4)
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x- 拡張CNNモデルを定義します。各畳み込み層の後にバッチ正規化を適用し、全結合層の後にドロップアウトを適用します。畳み込み層には拡張畳み込み(dilation)を使用しています。
モデルのインスタンス化
model = DilatedCNN().to(device)損失関数とオプティマイザの設定
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)トレーニングループ
num_epochs = 10
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(train_loader.dataset)
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {epoch_loss:.4f}")
# 検証ループ
model.eval()
val_running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_running_loss += loss.item() * inputs.size(0)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
val_loss = val_running_loss / len(val_loader.dataset)
val_accuracy = correct / total
print(f"Validation Loss: {val_loss:.4f}, Accuracy: {val_accuracy:.4f}")
print("Training complete")バッチ正規化は各畳み込み層の後に適用され、ドロップアウトは全結合層の後に適用されます。これにより、モデルのトレーニングが安定し、過学習を防ぐことができます。また、拡張畳み込みを使用することで、受容野を拡大しつつ計算量を増やさずに情報を集約することができます。
論文1:WaveNet (2016):拡張畳み込みを用いた音声生成モデル。

- 長距離依存のモデリング
- 膨張型畳み込み(Dilated Convolution)は、計算コストを抑えながらフィルタの適用範囲を広げることで、大きな受容野を確保します。この仕組みにより、音声波形の長距離の特徴を効率よく捉えることができます。
- 指数的受容野の拡大
- 膨張型畳み込みでは、膨張係数を指数的に増やす設計を採用しています。これにより、層を重ねるたびに受容野が広がり、深いモデルでも広範囲の時間的特徴を効率的に捉えられます。
- 因果構造の保持
- 膨張型因果畳み込みは、時系列データの順序を守りながら処理する仕組みです。これにより、未来のデータに依存せず、自然な音声生成に必要な時間的な因果関係を正確に保つことができます。
論文2:DeepLab (2016):セマンティックセグメンテーションで拡張畳み込みを使用。

- 解像度制御と視野拡大
- Dilated Convolution(アトラス畳み込み)は、畳み込みカーネルに間隔(空隙)を挿入することで、解像度を落とさずにフィルタの受容野を拡大。これにより、広い文脈情報を効率的に取り入れられる。
- 計算コストとパラメータの削減
- カーネルサイズの実効的な拡大により、追加の計算コストやモデルパラメータを増やすことなく、マルチスケール特徴の抽出を実現する省エネ設計が可能。
- 密な予測タスクへの適用性
- Dilated Convolutionは、セマンティックセグメンテーションのような密な予測タスクで、高解像度の特徴マップを生成し、空間的に精密なセグメンテーションを実現する基盤技術として機能する。
転移学習を用いた効率的な学習を体験する
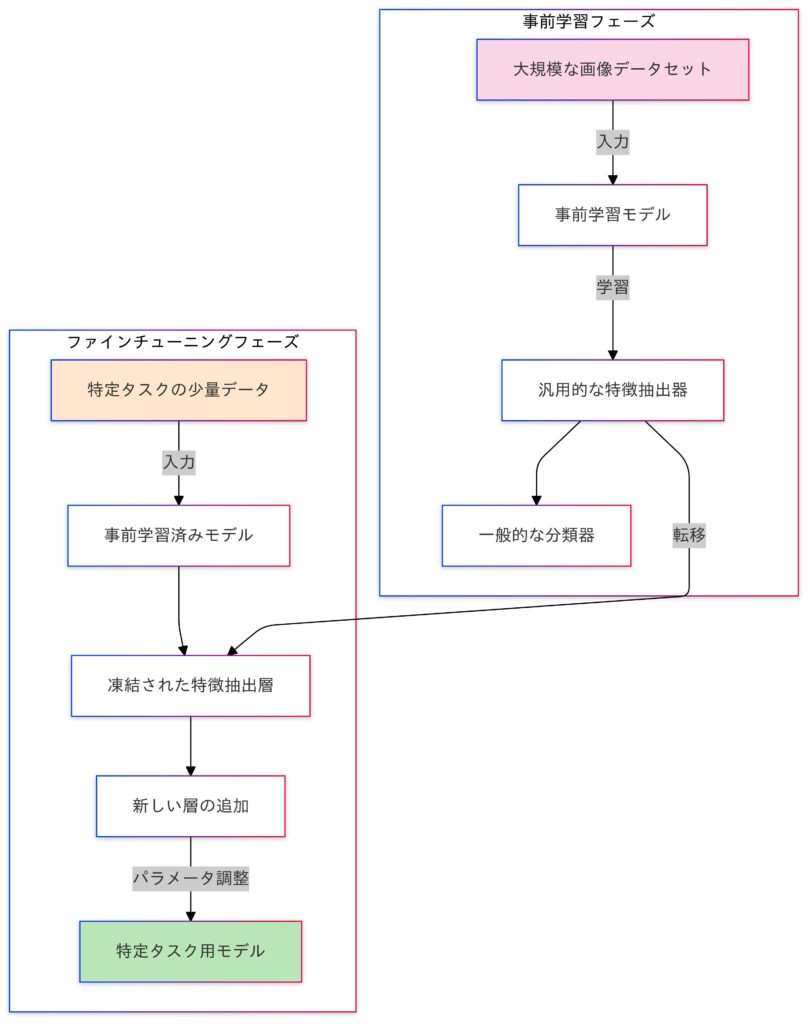
転移学習は、ある領域やタスクで学習されたモデル(事前学習済みモデル)の知識を、新しいタスクに活用する学習手法です。主に以下の2つのプロセスで構成されます。
- 事前学習 (Pretraining)
- 事前学習は、ImageNetやWikipediaのような一般的なデータセットを使って、モデルに汎用的な特徴を学習させるプロセスです。これにより、多様なタスクで活用できる基盤を構築し、特徴抽出器として機能します。事前学習済みモデルは、一般的な特徴を捉えた状態で学習済みのため、ターゲットタスクへの適応が効率的に行えます。
- ファインチューニング
- ファインチューニング(Fine-tuning)は、事前学習済みモデルを特定のタスクに合わせて調整するプロセスです。医療画像や文書など、タスクに特化したデータを使い、必要な特徴を学習して性能を向上させます。この過程では、モデルの一部または全てのパラメータを更新し、タスクに最適化します。
転移学習における両者の関係
事前学習とファインチューニングは、転移学習を支える重要なプロセスです。
事前学習では、一般的なデータセットを使い、モデルの基盤となる低レベルの特徴(例: エッジや形状)を学習します。一方、ファインチューニングは、この基盤を特定のタスクに最適化するプロセスで、必要な高レベルの特徴を新たに学習します。この組み合わせにより、少ないラベル付きデータでも高い性能を発揮できます。
ただし、事前学習がターゲットタスクに適応できるかは、ソースタスクとターゲットタスクの類似性やデータの質に左右されます。
つまり、事前学習が成功すれば、ファインチューニングの効果も向上します。
数式:
転移学習では、学習済みモデル $f(x; \theta_{pre})$ の重み $\theta_{pre}$ を新しいタスクに活用します。
- 事前学習
$$\theta_{\text{pre}} = \underset{\theta}{\arg\min} \frac{1}{N} \sum_{i=1}^{N} \mathcal{L}_{\text{pre}} \left( y_i, f(x_i; \theta) \right)$$
- $\mathcal{L}_{\text{pre}}$:事前タスクの損失関数(例: クロスエントロピー)。
- $N$:サンプル数。
- ファインチューニング
$$\theta_{\text{new}} = \underset{\theta}{\arg\min} \frac{1}{M} \sum_{j=1}^{M} \mathcal{L}_{\text{new}} \left( y_j, f(x_j; \theta) \right)$$
- 事前学習で得た$\theta_{\text{pre}}$を初期値として、$\mathcal{L}_{\text{new}}$(新タスク用の損失関数)を最小化。
目的と課題:
| 目的 | 詳細 |
|---|---|
| 効率的な学習 | ラベル付きデータが限られる場合でも、高性能なモデルを構築。 |
| 計算リソースの節約 | 事前学習済みモデルを再利用することで、計算コストを削減。 |
| 汎化性能の向上 | 大規模データセットで学習された特徴を活用して、新タスクに対して良好な性能を発揮。 |
| 課題 | 詳細 |
|---|---|
| タスクの相違 | 事前タスクと新タスクが異なる場合、学習が難しい(例: 自然画像モデルを医療画像に適応)。 |
| 過学習のリスク | 小規模なデータでファインチューニングする場合、過学習が発生しやすい。 |
| 計算リソース依存 | 学習済みモデルが大規模である場合、ファインチューニングにも高い計算リソースが必要。 |
メリットとデメリット
| メリット | 詳細 |
|---|---|
| 学習時間の短縮 | 既存モデルを活用するため、ゼロから学習するよりも高速。 |
| 高性能なモデル | 大規模データセットで学習された特徴を活用可能。 |
| 小規模データ対応 | ラベル付きデータが少ない場合でも良好な性能を達成。 |
| デメリット | 詳細 |
|---|---|
| 適応性の制限 | 事前タスクと新タスクの相違が大きい場合、性能が低下。 |
| モデルサイズ | 事前学習済みモデルが非常に大きい場合、メモリや計算コストが増大。 |
| 微調整の困難さ | ファインチューニング時に適切なハイパーパラメータの選択が必要。 |
適用例:
| 分野 | 適用例 |
|---|---|
| 画像分類 | ImageNetで事前学習したResNetを、医療画像分類タスクに適応。 |
| 自然言語処理 (NLP) | BERTやGPTモデルをカスタム文書分類タスクにファインチューニング。 |
| 音声認識 | 音声波形データに対する転移学習で、話者認識や感情認識を実現。 |
| 金融データ分析 | 株価予測モデルに事前学習済みの時系列モデルを適応。 |
論文1:ResNet
事前学習における特筆すべき点
- ResNetは、152層という非常に深いネットワークを効率よく訓練できるため、ImageNetのような大規模データセットから高精度な特徴を抽出する能力を持っています。
- 残差学習を採用することで、深いネットワークの訓練がスムーズになり、学習がより安定するようになります。
- ボトルネック構造を採用することで計算コストを削減しながら、特徴を効率的に再利用できるようになり、事前学習モデルの性能が向上します。
ファインチューニングにおける特筆すべき点
- 事前学習モデルをCOCOやPASCAL VOCなどのタスクに合わせてファインチューニングすることで、転移学習の効果が大幅に向上します。
- ResNetの高次元な特徴を活用することで、物体検出やセグメンテーションのタスクで非常に高い精度を実現しています。
- 残差接続の優れた汎化性能により、新しいデータセットにも効率よく適応できます。
論文2:BERT

- 事前学習モデルの革新
- BERTは「双方向Transformer」を用いた事前学習モデルを提案しました。Masked Language Model(MLM)とNext Sentence Prediction(NSP)という新しいタスクを導入することで、文脈を深く理解し、さまざまなタスクへの転移性能を大幅に向上させています。
- ファインチューニングの汎用性
- BERTは、事前学習したモデルを微調整するだけで、分類や質問応答など幅広い自然言語処理タスクに対応可能です。専用のモデル設計が不要で、汎用性と効率性の高いアプローチを実現しました。
- 圧倒的な転移性能
- BERTは、GLUEやSQuADなどのベンチマークで、転移学習によって最先端の性能を達成しました。特にSQuAD v1.1ではF1スコア93.2を記録し、従来のモデルを大きく上回る成果を示しています。
転移学習の実装例:
ライブラリのインポート
import torch
import torch.nn as nn
import torchvision.models as models
from torchvision import datasets, transforms事前学習済みResNetをロード
model = models.resnet18(pretrained=True)事前学習済みのResNet-18モデルをロードします。
最終層を新タスク用に置き換え
num_features = model.fc.in_features
model.fc = nn.Sequential(
nn.Linear(num_features, 512),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(512, 2) # 例: 2クラス分類
)最終層を2クラス分類用に置き換えます。新しい全結合層の前にReLU活性化関数とドロップアウトを追加しています。
デバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
model = model.to(device)転移学習用のデータセット準備
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
train_dataset = datasets.FakeData(transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)データの前処理を定義し、転移学習用のデータセットを準備します。ここでは、FakeDataを使用していますが、実際のデータセットに置き換えることができます。
損失関数と最適化
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)ファインチューニングの学習ループ
model.train()
for epoch in range(5):
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(train_loader.dataset)
print(f"Epoch {epoch+1}, Loss: {epoch_loss:.4f}")
print("Training complete")モデルをトレーニングモードに設定し、ファインチューニングを行います。各エポックの損失を表示します。
転移学習の派生手法について
多くの転移学習の派生手法はファインチューニングに焦点を当てていますが、事前学習の工夫に基づくものも存在します。それぞれの派生手法が、どのプロセスで効果を発揮するかを明確にすることで、適切な解釈と応用が可能になります。
したがって、「派生手法のほとんどはファインチューニングに属する」と解釈して間違いありませんが、事前学習に特化した方法や両方を跨ぐ手法もあることに留意してください。
次の章では、事前学習に関連する派生手法、ファインチューニングに関連する派生手法、両方にまたがる派生手法を紹介していきます。
事前学習に関連する派生手法
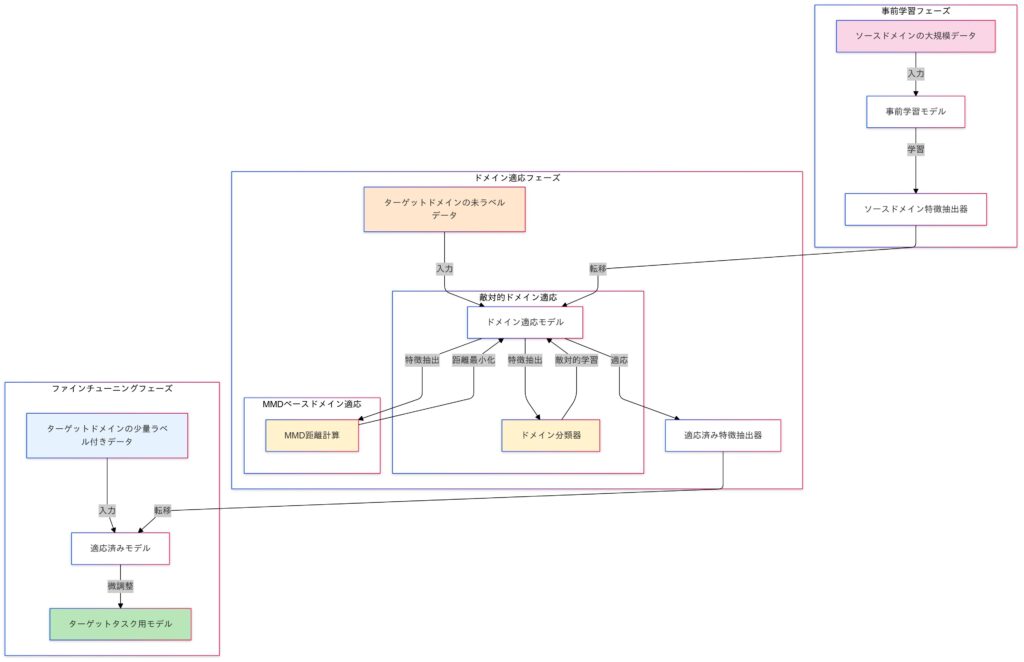
事前学習は、大規模データセットを使って一般的な特徴を学習するプロセスです。一方、事前学習済みモデルを特定のタスクに適用する際には、ドメイン適応(Domain Adaptation)という手法が用いられることがあります。ドメイン適応は、事前学習で使用したデータ(ソースドメイン)と適応先のデータ(ターゲットドメイン)の分布の違いを調整し、特徴抽出器をターゲットデータに適応させることで、転移学習の効果を高めます。
Domain Adaptation(ドメイン適応)
Domain Adaptation は、事前学習モデルが適用されるドメイン(データの分布)が異なる場合に、そのギャップを埋めて適応させる技術です。特に、ソースドメイン(学習に用いたデータ)とターゲットドメイン(適用対象のデータ)の分布が異なる場合でも、転移学習を有効に活用するための手法です。
特徴
- ソースドメインで学習したモデルをターゲットドメインに適応させる。
- ターゲットドメインのデータがラベル付きデータとして十分に利用できない場合でも、高い精度を達成。
数式での表現:
ソースドメイン $(X_s, Y_s)$とターゲットドメイン $(X_t, Y_t)$のデータ分布$P_s(X,Y)$と $P_t(X, Y)$が異なる場合を考えます。
Domain Adaptation の目標は、以下を満たすようなモデル $f(X)$ を見つけることです。
$$P_s(X, Y) \neq P_t(X, Y)ただし、P_s(Y \mid X) \approx P_t(Y \mid X)$$
- $P_s(X,Y)$:ソースドメインの分布。
- $P_t(X,Y)$:ターゲットドメインの分布。
- $P_s(Y \mid X)$:ソースデータにおける条件付き分布。
- $P_t(Y \mid X)$:ターゲットデータにおける条件付き分布。
方法
- 分布間のギャップを削減
- 入力データ空間、特徴空間、または出力空間における分布間の違いを最小化。
- 一般的に、分布距離(例:MMD、Wasserstein距離)を最小化するアプローチが使用される。
目的と課題
目的:
- ソースデータとターゲットデータの分布差異を克服し、ターゲットドメインで高いパフォーマンスを達成する。
- ターゲットドメインのラベルなしデータを活用して、より汎用的なモデルを構築。
課題:
- 分布差異の特定
- データ間の分布差異がどの空間(入力、特徴、出力)に存在するかを特定することが重要。
- ターゲットデータの不足
- ターゲットデータのラベルが少ない場合、適応の効果が制限される。
メリットとデメリット
| メリット | 詳細 |
|---|---|
| ラベルコスト削減 | ターゲットドメインのラベル付きデータが少なくても対応可能。 |
| 既存モデルの再利用 | ソースドメインで学習したモデルを活用し、効率的な学習が可能。 |
| デメリット | 詳細 |
|---|---|
| 適応の限界 | 分布差が大きすぎる場合、モデルの性能が低下。 |
| 適応に伴う計算コスト | 分布差を削減するための追加計算が必要。 |
| オーバーフィッティングのリスク | 分布ギャップを過度に削減しようとすると、汎化性能が低下。 |
適用例:
| 分野 | 適用例 |
|---|---|
| 画像処理 | – 医療画像: 自然画像で事前学習したモデルをX線画像やMRI画像に適応。 |
| – 天候条件の違い: 晴天で学習したモデルを曇天や夜間に適応。 | |
| 自然言語処理 | – 言語間の適応: 英語で学習したモデルを他の言語(日本語、ドイツ語など)に適応。 |
| 音声認識 | – 話者の違い: 特定の話者で学習したモデルを他の話者に適応。 |
| 異常検知 | – 産業データ: 正常な操作データから学習したモデルを異常検知に適応。 |
ドメイン適応の種類
ドメイン適応は、ソースドメイン(事前学習に使用したデータセット)とターゲットドメイン(適用先のデータセット)の分布差を克服する技術です。この分布差を調整するための代表的な手法として、敵対的ドメイン適応とMMD距離を用いたドメイン適応があります。
敵対的ドメイン適応
敵対的ドメイン適応は、ソースドメインとターゲットドメインの特徴分布を一致させるために、敵対的学習を使用します。主にジェネレータ(特徴抽出器)と判別器(ドメイン分類器)が競争することで、分布の一致を学習します。
数式:
- 特徴抽出器 $G$
- ソースデータ $X_S$ とターゲットデータ $X_T$ を共通の特徴空間にマッピングします。
$$Z_S = G(X_S), \quad Z_T = G(X_T)$$
- 判別器 $D$
- 特徴 $Z$ がソースデータ由来かターゲットデータ由来かを分類します。
損失関数
$$L_D = – \mathbb{E}_{Z_S} [\log D(Z_S)] – \mathbb{E}_{Z_T} [\log (1 – D(Z_T))]$$
- ジェネレータの更新
- 判別器を騙すように特徴抽出器を更新します。
損失関数
$$L_G = – \mathbb{E}_{Z_T} [\log D(Z_T)]$$
- 全体の目標
- ジェネレータと判別器を交互にトレーニングして以下のミニマックス問題を解きます。
$$\min_G \max_D L_D$$
特徴と適用例
| 特徴 | 説明 |
|---|---|
| 分布の非線形的なギャップを埋める | ソースドメインとターゲットドメイン間の非線形な分布差異を効果的に縮小します。 |
| 高次元データへの適用に適している | 画像や音声などの高次元データに対して効果的に機能します。 |
| 適用分野 | 具体例 |
|---|---|
| 医療画像 | 異なる機器や病院で取得されたデータ間の差異を調整し、モデルの精度を向上させる。 |
| 自然画像 | 異なるカメラや照明条件で撮影された画像の差異を補正し、認識性能を改善する。 |
敵対的ドメイン適応の実装例:
このコードでは、ドメイン識別器を追加し、ソースドメインとターゲットドメインの特徴を区別できないように特徴抽出器を訓練します。
ライブラリのインポート
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torchvision import datasets, models
from torch.utils.data import DataLoaderデバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")データの前処理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])画像を224×224にリサイズし、テンソルに変換し、正規化します。
ソースドメインとターゲットドメインのデータセット準備
source_dataset = datasets.FakeData(transform=transform)
source_loader = DataLoader(source_dataset, batch_size=32, shuffle=True)
target_dataset = datasets.FakeData(transform=transform)
target_loader = DataLoader(target_dataset, batch_size=32, shuffle=True)ソースドメインとターゲットドメインのデータセットを準備します。ここでは、FakeDataを使用していますが、実際のデータセットに置き換えることができます。
特徴抽出器の定義
class FeatureExtractor(nn.Module):
def __init__(self):
super(FeatureExtractor, self).__init__()
resnet = models.resnet18(pretrained=True)
self.features = nn.Sequential(*list(resnet.children())[:-1]) # 最後の全結合層を除く
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
return x事前学習済みのResNet-18を使用して特徴抽出器を定義します。最後の全結合層を除きます。
分類器の定義
class Classifier(nn.Module):
def __init__(self, num_classes=2):
super(Classifier, self).__init__()
self.fc = nn.Linear(512, num_classes)
def forward(self, x):
x = self.fc(x)
return x特徴抽出器の出力を受け取る分類器を定義します。
ドメイン識別器の定義
class DomainDiscriminator(nn.Module):
def __init__(self):
super(DomainDiscriminator, self).__init__()
self.fc = nn.Sequential(
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, 2)
)
def forward(self, x):
x = self.fc(x)
return x特徴抽出器の出力を受け取るドメイン識別器を定義します。
feature_extractor = FeatureExtractor().to(device)
classifier = Classifier().to(device)
domain_discriminator = DomainDiscriminator().to(device)モデルをインスタンス化し、デバイスに移動します。
損失関数と最適化
criterion = nn.CrossEntropyLoss()
optimizer_fe = optim.Adam(feature_extractor.parameters(), lr=0.001)
optimizer_cl = optim.Adam(classifier.parameters(), lr=0.001)
optimizer_dd = optim.Adam(domain_discriminator.parameters(), lr=0.001)ドメイン適応の学習ループ
num_epochs = 10
for epoch in range(num_epochs):
feature_extractor.train()
classifier.train()
domain_discriminator.train()
running_loss_cl = 0.0
running_loss_dd = 0.0
for (source_inputs, source_labels), (target_inputs, _) in zip(source_loader, target_loader):
source_inputs, source_labels = source_inputs.to(device), source_labels.to(device)
target_inputs = target_inputs.to(device)
# 特徴抽出
source_features = feature_extractor(source_inputs)
target_features = feature_extractor(target_inputs)
# 分類器の更新
optimizer_fe.zero_grad()
optimizer_cl.zero_grad()
source_outputs = classifier(source_features)
loss_cl = criterion(source_outputs, source_labels)
loss_cl.backward()
optimizer_fe.step()
optimizer_cl.step()
running_loss_cl += loss_cl.item() * source_inputs.size(0)
# ドメイン識別器の更新
optimizer_dd.zero_grad()
source_domain_labels = torch.zeros(source_inputs.size(0), dtype=torch.long).to(device)
target_domain_labels = torch.ones(target_inputs.size(0), dtype=torch.long).to(device)
domain_outputs_source = domain_discriminator(source_features.detach())
domain_outputs_target = domain_discriminator(target_features.detach())
loss_dd_source = criterion(domain_outputs_source, source_domain_labels)
loss_dd_target = criterion(domain_outputs_target, target_domain_labels)
loss_dd = (loss_dd_source + loss_dd_target) / 2
loss_dd.backward()
optimizer_dd.step()
running_loss_dd += loss_dd.item() * (source_inputs.size(0) + target_inputs.size(0))
epoch_loss_cl = running_loss_cl / len(source_loader.dataset)
epoch_loss_dd = running_loss_dd / (len(source_loader.dataset) + len(target_loader.dataset))
print(f"Epoch {epoch+1}/{num_epochs}, Classification Loss: {epoch_loss_cl:.4f}, Domain Discriminator Loss: {epoch_loss_dd:.4f}")
print("Training complete")Epoch 1/10, Classification Loss: 0.1912, Domain Discriminator Loss: 0.7115
Epoch 2/10, Classification Loss: 0.0785, Domain Discriminator Loss: 0.6933
…
Epoch 9/10, Classification Loss: 0.0095, Domain Discriminator Loss: 0.6934
Epoch 10/10, Classification Loss: 0.0053, Domain Discriminator Loss: 0.6932特徴抽出器、分類器、およびドメイン識別器をトレーニングし、各エポックの損失を表示します。
つまりこのコード例では、敵対的ドメイン適応を使用してソースドメインとターゲットドメインの分布間のギャップを削減する方法を示しています。これにより、ソースドメインとターゲットドメインの分布間のギャップを削減し、モデルの性能を向上させることができます。
論文:『Adversarial Discriminative Domain Adaptation』

- 新手法ADDAの提案
- 新手法「Adversarial Discriminative Domain Adaptation (ADDA)」は、3つの特徴を持つ手法です。まず、識別モデルを活用し、次にソースとターゲット間で重みを非対称に共有します。そして、敵対的損失を取り入れることで、ラベルのないターゲットデータにも高い適応性能を発揮します。
- 包括的なフレームワークの提示
- 敵対的ドメイン適応における既存手法を包括する新しいフレームワークを提案しました。このフレームワークにより、これまでの手法の位置づけが明確になり、新たに効果的なアプローチを設計する基盤が整いました。
- 優れた適応性能
- MNISTやUSPS、SVHNといったデータセットで、提案手法は競合を上回る性能を発揮しました。さらに、RGB画像から深度画像への変換といった難易度の高いタスクでも有効性を確認しています。
MMD距離を用いたドメイン適応
MMD(Maximum Mean Discrepancy)は、ソースドメインとターゲットドメインの特徴分布の差異を測定し、その平均ベクトル間の距離を最小化することで、両者の分布を一致させる手法です。これにより、異なるデータ間の分布の違いを調整し、モデルの適応能力を向上させます。
数式:
- MMD距離
$$\text{MMD}^2(P, Q) = \left\| \mathbb{E}_{x \sim P}[\phi(x)] – \mathbb{E}_{x \sim Q}[\phi(x)] \right\|^2$$
- $P$:ソースドメインの分布。
- $Q$:ターゲットドメインの分布。
- $ϕ(x)$:高次元の再現核ヒルベルト空間(RKHS)への写像。
- 最適化目標
- 特徴抽出器 $G$ を調整して、MMD距離を最小化。
$$\min_{G} \text{MMD}^2(G(X_S), G(X_T))$$
特徴と適用例
| 特徴 | 説明 |
|---|---|
| 理論的にシンプルで、カーネル法を用いて非線形分布差にも対応 | MMDは理論的に単純であり、カーネル法を活用することで、非線形な分布の違いにも対応できます。 |
| 高速で実装が容易 | MMDは計算効率が高く、実装も比較的簡単です。 |
| 適用分野 | 具体例 |
|---|---|
| 時系列データ | 異なるセンサーから取得されたデータ間の差異を調整し、モデルの精度を向上させる。 |
| 自然言語処理 | 異なるテキストコーパス間のドメイン差を補正し、モデルの適応性を高める。 |
MMD距離を用いたドメイン適応の実装例:
このコードでは、MMD距離を計算し、ソースドメインとターゲットドメインの特徴分布を一致させるように特徴抽出器を訓練します。これにより、ソースドメインとターゲットドメインの分布間のギャップを削減し、モデルの性能を向上させることができます。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torchvision import datasets, models
from torch.utils.data import DataLoader
# デバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
# データの前処理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# ソースドメインとターゲットドメインのデータセット準備
source_dataset = datasets.FakeData(transform=transform)
source_loader = DataLoader(source_dataset, batch_size=32, shuffle=True)
target_dataset = datasets.FakeData(transform=transform)
target_loader = DataLoader(target_dataset, batch_size=32, shuffle=True)
# 特徴抽出器の定義(事前学習済みResNetを使用)
class FeatureExtractor(nn.Module):
def __init__(self):
super(FeatureExtractor, self).__init__()
resnet = models.resnet18(pretrained=True)
self.features = nn.Sequential(*list(resnet.children())[:-1]) # 最後の全結合層を除く
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
return x
# 分類器の定義
class Classifier(nn.Module):
def __init__(self, num_classes=2):
super(Classifier, self).__init__()
self.fc = nn.Linear(512, num_classes)
def forward(self, x):
x = self.fc(x)
return x
# RBFカーネルの計算
def rbf_kernel(x, y, gamma=1.0):
diff = x.unsqueeze(1) - y.unsqueeze(0)
return torch.exp(-gamma * (diff ** 2).sum(2))
# MMD損失の計算
def mmd_loss(source_features, target_features, gamma=1.0):
K_ss = rbf_kernel(source_features, source_features, gamma)
K_tt = rbf_kernel(target_features, target_features, gamma)
K_st = rbf_kernel(source_features, target_features, gamma)
return K_ss.mean() + K_tt.mean() - 2 * K_st.mean()
# モデルのインスタンス化
feature_extractor = FeatureExtractor().to(device)
classifier = Classifier().to(device)
# 損失関数と最適化
criterion = nn.CrossEntropyLoss()
optimizer_fe = optim.Adam(feature_extractor.parameters(), lr=0.001)
optimizer_cl = optim.Adam(classifier.parameters(), lr=0.001)
# ドメイン適応の学習ループ
num_epochs = 10
for epoch in range(num_epochs):
feature_extractor.train()
classifier.train()
running_loss_cl = 0.0
running_loss_mmd = 0.0
for (source_inputs, source_labels), (target_inputs, _) in zip(source_loader, target_loader):
source_inputs, source_labels = source_inputs.to(device), source_labels.to(device)
target_inputs = target_inputs.to(device)
# 特徴抽出
source_features = feature_extractor(source_inputs)
target_features = feature_extractor(target_inputs)
# 分類器の更新
optimizer_fe.zero_grad()
optimizer_cl.zero_grad()
source_outputs = classifier(source_features)
loss_cl = criterion(source_outputs, source_labels)
# MMD距離の計算
loss_mmd = mmd_loss(source_features, target_features)
# 総損失
loss = loss_cl + loss_mmd
loss.backward()
optimizer_fe.step()
optimizer_cl.step()
running_loss_cl += loss_cl.item() * source_inputs.size(0)
running_loss_mmd += loss_mmd.item() * source_inputs.size(0)
epoch_loss_cl = running_loss_cl / len(source_loader.dataset)
epoch_loss_mmd = running_loss_mmd / len(source_loader.dataset)
print(f"Epoch {epoch+1}/{num_epochs}, Classification Loss: {epoch_loss_cl:.4f}, MMD Loss: {epoch_loss_mmd:.4f}")
print("Training complete")論文:『Unsupervised Domain Adaptation with Residual Transfer Networks』

- MMDによる特徴分布の一致
- MMD(最大平均差)を損失関数に組み込み、ソースドメインとターゲットドメインの特徴分布をRKHS上で一致させる。これにより、ドメイン間のギャップを効果的に縮小し、適応性能を向上。
- 特徴統合と適応の統一設計
- CNNの複数の特徴層をテンソル積で統合し、深層特徴と分類器の適応を同時に最適化します。これにより、従来のように適応を別々に行う方法と比べて、より効率的で統一的なドメイン適応が実現できます。
- 分類器適応の新アプローチ
- 残差学習を活用して、分類器間の微細な差異を調整します。これにより、分類器の自由度を維持しつつターゲットデータへの適応が可能となり、より実用的なシナリオにも柔軟に対応できるようになります。
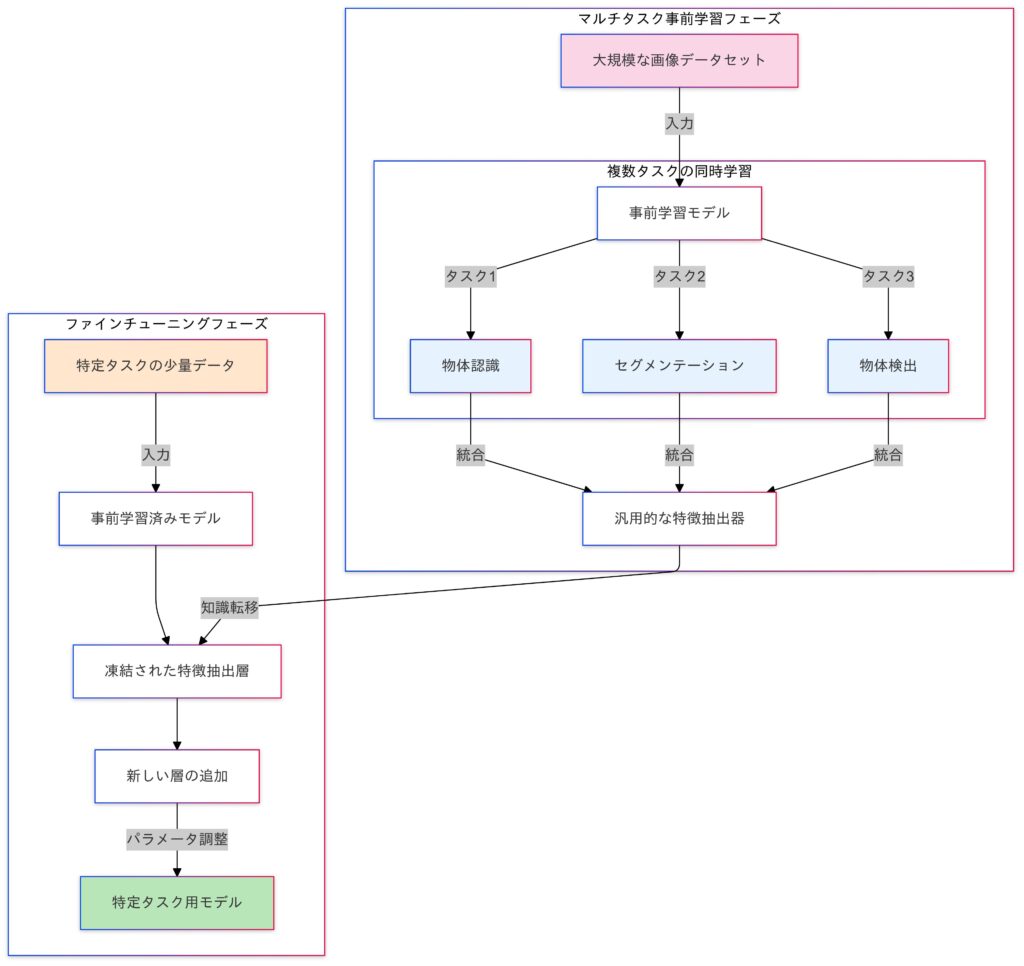
マルチタスク学習
マルチタスク学習は、転移学習の事前学習段階で複数の関連タスクを同時に学習する手法です。これにより、各タスク間の共通情報を活用し、モデルの汎化性能を向上させます。
特徴:
| 特徴 | 説明 |
|---|---|
| タスク間の情報共有 | 複数のタスクを同時に学習することで、各タスクが互いに有益な情報を共有し、学習効率を高めます。 |
| モデルの効率化 | 共通のモデル部分を複数のタスクで共有するため、全体のモデルサイズや計算コストを削減できます。 |
| 過学習の抑制 | 関連タスクの同時学習により、特定のタスクへの過度な適応を防ぎ、モデルの汎化能力を強化します。 |
| データの有効活用 | 各タスクのデータを組み合わせて使用することで、データ不足の問題を緩和し、モデルの性能向上に寄与します。 |
マルチタスク学習のイメージ
数式:
- 目的関数
- マルチタスク学習では、各タスク $T_i$ に対する損失関数 $L_i$ を組み合わせた全体の損失関数を最小化します。
$$L_{\text{total}} = \sum_{i=1}^{N} \alpha_i L_i$$
$N$:タスクの数。$α_i$:タスク $T_i$ の重み。$L_i$:タスク $T_i$ の損失関数。
- 共有表現
- 入力データ $x$ を共有部分 $h(x; \theta_s)$ にマッピングし、それぞれのタスク用の部分モデル $g_i(h(x; \theta_s); \theta_i)$ に渡します。
$$y_i = g_i(h(x; \theta_s); \theta_i)$$
$θ_s$:共有パラメータ。$θ_i$:タスク $T_i$ のタスク固有パラメータ。
目的と課題
| 目的 | 説明 |
|---|---|
| 汎化性能の向上 | 関連タスク間の知識共有により、データ不足のタスクでもモデルの性能を向上させます。 |
| 効率的な学習 | 一つのモデルで複数のタスクを学習するため、計算リソースを削減できます。 |
| モデルの簡略化 | 複数のタスクに対して一貫したモデルを提供し、全体の構造を簡素化します。 |
| 課題 | 説明 |
|---|---|
| タスク間の競合 | 異なるタスク間で学習が干渉し、一方のタスクが他方の性能を阻害する可能性があります。 |
| 重みの調整 | 損失関数の重みを適切に調整しないと、一部のタスクの学習が優先され、他のタスクの性能が低下することがあります。 |
| データの不均衡 | タスクごとにデータの量や質が異なる場合、モデルの学習バランスを保つことが難しくなります。 |
メリットとデメリット
| メリット | 説明 |
|---|---|
| パラメータの効率的利用 | 複数のタスクがパラメータを共有するため、モデルサイズを抑えられる。 |
| データ効率の向上 | 少量データのタスクでも他のタスクからの知識を活用。 |
| 汎化能力の向上 | タスク間の関連性を利用して、未知のデータに対する性能を向上。 |
| デメリット | 説明 |
|---|---|
| タスク間の競合 | 関連性の低いタスクを同時に学習すると性能が低下する。 |
| モデル設計の複雑さ | 共有部分とタスク固有部分の設計や損失関数の重み付けが難しい。 |
適用例:
| 適用例 | 説明 |
|---|---|
| 自然言語処理(NLP) | 質問応答、文書分類、感情分析を同時に学習。 |
| コンピュータビジョン | 物体検出、画像分類、セグメンテーションを一つのモデルで学習。 |
| 医療分野 | 複数の疾患を同時に予測。 |
| ロボティクス | センサー入力から同時に経路計画と物体認識を行う。 |
マルチタスク学習の実装例:
このコードは、PyTorchを使用してマルチタスク学習モデルを構築し、事前学習を行った後、新しいタスク(感情分析)に対して転移学習を行う例です。
マルチタスク学習
マルチタスク学習では、複数のタスクを同時に学習することで、各タスクの性能を向上させることを目指します。この例では、質問応答タスクと文書分類タスクを同時に学習するモデルを構築しています。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# 共有部分(エンコーダー)
class SharedEncoder(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(SharedEncoder, self).__init__()
self.encoder = nn.LSTM(input_dim, hidden_dim, batch_first=True)
def forward(self, x):
_, (hidden, _) = self.encoder(x)
return hidden
# 質問応答タスク
class QuestionAnsweringTask(nn.Module):
def __init__(self, hidden_dim, output_dim):
super(QuestionAnsweringTask, self).__init__()
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
return self.fc(x)
# 文書分類タスク
class DocumentClassificationTask(nn.Module):
def __init__(self, hidden_dim, output_dim):
super(DocumentClassificationTask, self).__init__()
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
return self.fc(x)
# マルチタスク学習モデル
class MultitaskModel(nn.Module):
def __init__(self, input_dim, hidden_dim, qa_output_dim, doc_output_dim):
super(MultitaskModel, self).__init__()
self.shared_encoder = SharedEncoder(input_dim, hidden_dim)
self.qa_task = QuestionAnsweringTask(hidden_dim, qa_output_dim)
self.doc_task = DocumentClassificationTask(hidden_dim, doc_output_dim)
def forward(self, x):
shared_features = self.shared_encoder(x)
# 最終層の出力はバッチ次元を含むため、次元を調整
qa_output = self.qa_task(shared_features).squeeze(0)
doc_output = self.doc_task(shared_features).squeeze(0)
return qa_output, doc_output新しいタスク(感情分析)のためのモデル
class SentimentAnalysisTask(nn.Module):
def __init__(self, hidden_dim, output_dim):
super(SentimentAnalysisTask, self).__init__()
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
return self.fc(x)事前学習済みモデルのロードと事前学習
input_dim = 10
hidden_dim = 20
qa_output_dim = 5
doc_output_dim = 3
pretrained_model = MultitaskModel(input_dim, hidden_dim, qa_output_dim, doc_output_dim)
X_pretrain = torch.randn(100, 5, input_dim)
qa_labels_pretrain = torch.randn(100, qa_output_dim)
doc_labels_pretrain = torch.randint(0, doc_output_dim, (100,))
pretrain_dataset = TensorDataset(X_pretrain, qa_labels_pretrain, doc_labels_pretrain)
pretrain_loader = DataLoader(pretrain_dataset, batch_size=32)
criterion_qa = nn.MSELoss()
criterion_doc = nn.CrossEntropyLoss()
optimizer_pretrain = optim.Adam(pretrained_model.parameters(), lr=0.001)
for epoch in range(5):
for batch_X, batch_qa_labels, batch_doc_labels in pretrain_loader:
optimizer_pretrain.zero_grad()
qa_output, doc_output = pretrained_model(batch_X)
loss_qa = criterion_qa(qa_output, batch_qa_labels)
loss_doc = criterion_doc(doc_output, batch_doc_labels)
loss = loss_qa + loss_doc
loss.backward()
optimizer_pretrain.step()
print(f"Pre-training Epoch {epoch+1}, Loss: {loss.item():.4f}")新しいタスク用のモデルを作成
sentiment_output_dim = 2
sentiment_model = SentimentAnalysisTask(hidden_dim, sentiment_output_dim)事前学習済みモデルのエンコーダーを新しいモデルにコピー
sentiment_model.fc.weight.data = pretrained_model.qa_task.fc.weight.data[:sentiment_output_dim, :].clone()
sentiment_model.fc.bias.data = pretrained_model.qa_task.fc.bias.data[:sentiment_output_dim].clone()事前学習済みモデルのエンコーダーの重みとバイアスを新しいモデルにコピーします。
新しいタスク用のデータ
X_sentiment = torch.randn(64, 5, input_dim)
sentiment_labels = torch.randint(0, sentiment_output_dim, (64,))
sentiment_dataset = TensorDataset(X_sentiment, sentiment_labels)
sentiment_loader = DataLoader(sentiment_dataset, batch_size=32)ファインチューニング
criterion_sentiment = nn.CrossEntropyLoss()
optimizer_sentiment = optim.Adam(sentiment_model.parameters(), lr=0.001)
shared_encoder = pretrained_model.shared_encoder
for epoch in range(10):
for batch_X, batch_sentiment_labels in sentiment_loader:
optimizer_sentiment.zero_grad()
with torch.no_grad():
shared_features = shared_encoder(batch_X)
shared_features = shared_features.squeeze(0)
sentiment_output = sentiment_model(shared_features)
loss = criterion_sentiment(sentiment_output, batch_sentiment_labels)
loss.backward()
optimizer_sentiment.step()
print(f"Fine-tuning Epoch {epoch+1}, Loss: {loss.item():.4f}")
print("転移学習完了")Pre-training Epoch 1, Loss: 2.2119
…
Pre-training Epoch 5, Loss: 2.1214
Fine-tuning Epoch 1, Loss: 0.6993
Fine-tuning Epoch 2, Loss: 0.6983
…
Fine-tuning Epoch 9, Loss: 0.6912
Fine-tuning Epoch 10, Loss: 0.6903
転移学習完了事前学習済みの共有エンコーダーを使用して感情分析タスクのファインチューニングを行います。
Pre-training(事前学習):
- モデルを大規模なデータセットで初期トレーニングし、一般的な特徴を学習する段階。
| 項目 | 内容 |
|---|---|
| 目的 | ・モデルが一般的な特徴を学習することを目的とし、大規模なデータセットで初期トレーニングを行います。 ・事前学習されたモデルは、特定のタスクに対して良い初期状態を提供します。 |
| データ | ・一般的に大規模で多様なデータセットが使用されます。 例: 画像認識モデルではImageNetデータセットがよく使用されます。 |
| プロセス | ・モデルは、一般的なタスク(例: 画像分類や言語モデル)に対してトレーニングされます。 ・この段階では、モデルは特定のタスクに特化していないため、広範な特徴を学習します。 |
| 例 | ・画像認識モデルのResNetやVGGは、ImageNetデータセットで事前学習されることが多いです。 ・言語モデルのBERTやGPTは、大規模なテキストコーパスで事前学習されます。 |
Fine-tuning(ファインチューニング):
- 事前学習済みモデルを特定のタスクやデータセットに適応させるために微調整する段階。
| 項目 | 内容 |
|---|---|
| 目的 | ・事前学習済みモデルを特定のタスクやデータセットに適応させる。 ・事前学習済みモデルの重みを初期状態として使用し、特定のタスクに対して微調整を行う。 |
| データ | ・特定のタスクに関連するデータセットを使用。 ・これらのデータセットは、事前学習に使用されたデータセットよりも小規模であることが多い。 |
| プロセス | ・事前学習済みモデルの重みを初期状態として使用し、特定のタスクに対してトレーニングを続ける。 ・この段階で、モデルは特定のタスクに特化した特徴を学習する。 |
| 例 | ・事前学習済みのResNetモデルを使用して、特定の画像分類タスク(例: 犬と猫の分類)に対してファインチューニングを行う。 ・事前学習済みのBERTモデルを使用して、特定の自然言語処理タスク(例: 感情分析や質問応答)に対してファインチューニングを行う。 |
論文1:『Caruana, R. (1997). “Multitask Learning”』
- マルチタスク学習の基礎的研究。タスク間の関連性を利用してモデル性能を向上させる手法を提案。

- マルチタスク学習の新しい視点
- この論文は、複数のタスクが情報を共有しながら学習するマルチタスク学習(MTL)の基盤を築きました。統計的データ増幅や関連する特徴の選択を活用することで、モデルの汎化性能を効果的に向上させています。
- 多様な応用可能性
- マルチタスク学習(MTL)は、医療診断、ロボティクス、時系列予測など、幅広い分野で活用できます。特に、肺炎リスクの予測や道路シミュレーションといった具体例では、優れた成果を実現しました。
- シングルタスク学習との比較優位
- マルチタスク学習(MTL)は、タスク間の関連性を活用することで、シングルタスク学習に比べて誤差を15~30%削減できます。このアプローチは汎用性が高く、ニューラルネットワーク以外の手法にも応用可能です。
論文2:『Ruder, S. (2017). “An Overview of Multitask Learning in Deep Neural Networks”』
- 深層学習におけるマルチタスク学習の包括的なレビュー。

- マルチタスク学習の基盤を体系化
- この論文は、マルチタスク学習(MTL)の基本概念を整理し、2つの主要な手法であるハードパラメータ共有とソフトパラメータ共有を詳しく解説。それぞれのメリットや適用できる場面を分かりやすく示しています。
- MTLが有効である理由の解明
- この論文は、マルチタスク学習(MTL)の効果を「データ拡張」「注意の集中」「盗み聞き効果」「表現のバイアス」「正則化」という観点で整理。複数タスクが協力することでモデルの汎化性能が向上する仕組みをわかりやすく説明しています。
- 最新手法と応用の多様性を紹介
- この論文では、Cross-stitch NetworksやSluice Networksといった最新のマルチタスク学習(MTL)手法を取り上げ、自然言語処理やコンピュータビジョンなど多様な分野での応用例を示し、MTLの可能性を広げています。
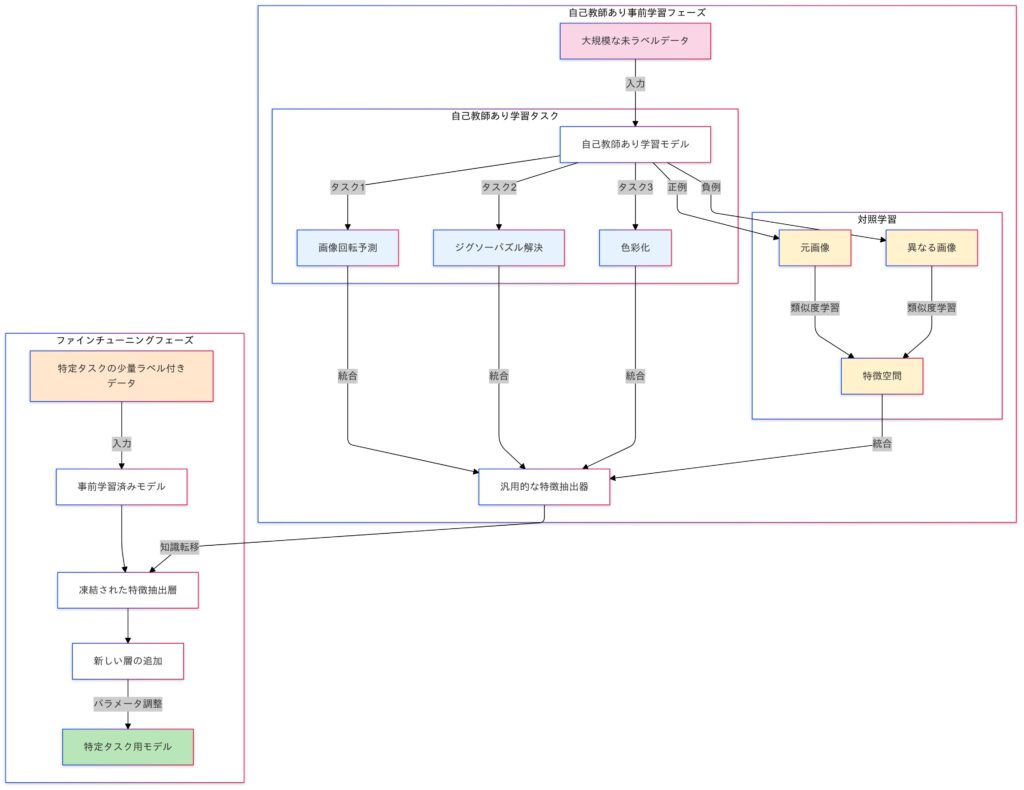
自己教師あり学習
自己教師あり学習(Self-Supervised Learning)は、ラベルなしデータから擬似ラベルを生成し、一般的な特徴を学習する手法です。これにより、ラベル付きデータの不足を補い、転移学習の事前学習として効果を発揮します。特に、SimCLRやBYOLなどの手法は視覚データの事前学習で注目されています。ただし、計算コストや擬似ラベルの品質が課題となるため、適切なデータ拡張やアルゴリズムの選択が重要です。
- SimCLR
- データ拡張と対照学習を組み合わせ、自己教師あり学習の性能を向上させる手法です。
- BYOL
- ネガティブペアを使用せず、自己教師ありで画像表現を学習する新しいアプローチです。
自己教師あり学習(対照学習を含む)のイメージ
数式:
- 目的関数
- 自己教師あり学習では、ラベルなしデータ $\mathcal{X} = \{x_1, x_2, \ldots, x_n\}$ を用いて、擬似的なラベル $\mathcal{Y} = \{y_1, y_2, \ldots, y_n\}$ を生成し、以下の目的関数を最適化します。
$$\mathcal{L} = \sum_{i=1}^{n} \mathcal{L}_{\text{self}}(f(x_i), y_i)$$
- $f(x_i)$:入力データ $x_i$ に対する特徴表現。
- $y_i$:自己教師あり学習により生成された擬似ラベル。
- $\mathcal{L}_{\text{self}}$:擬似ラベルに基づく損失関数(例: 対比学習の場合はコサイン類似性)。
- 対照学習 (Contrastive Learning)
- 2つの異なるビュー $x_i$ と $x_i’$ が似ていることを学習する場合、対照損失を以下で表します。
$$\mathcal{L}_{\text{contrastive}} = -\log \frac{\exp(\text{sim}(f(x_i), f(x_i’)) / \tau)}{\sum_{j=1}^{N} \exp(\text{sim}(f(x_i), f(x_j)) / \tau)}$$
sim: コサイン類似度。$τ$:温度ハイパーパラメータ。
メリットとデメリット
| メリット | デメリット |
|---|---|
| ラベルなしデータを利用して効率的に学習可能 | 擬似ラベルの品質が低いと性能が低下 |
| 転移学習の事前学習として柔軟性が高い | 高い計算コスト(特に大規模データでの学習) |
| タスク非依存の一般的な特徴学習が可能 | 適切なハイパーパラメータの選定が困難 |
| ラベル付きデータが少ない場合でも効果的 | 特定のタスクに特化しにくい場合がある |
適用例:
| 項目 | 説明 |
|---|---|
| 目的 | ラベルなしデータから特徴表現を学習し、転移学習の事前学習として活用する。 |
| 手法 | データ内の構造を利用して擬似ラベルを生成し、モデルを訓練する。 |
| 利点 | ラベル付きデータの不足を補い、新たなタスクへの適応力を向上させる。 |
| 課題 | 擬似ラベルの品質や計算コスト、適切なデータ拡張の選択が重要。 |
| 代表的な手法 | SimCLR、BYOL、MoCoなど。 |
| 適用例 | 画像認識、自然言語処理、音声処理、医療データ解析など。 |
自己教師あり学習(対照損失:InfoNCE損失関数の場合)
SimCLRの目的関数は、InfoNCE損失と呼ばれる対照損失を用いて定義されます。
InfoNCE損失:
$$\mathcal{L}_{\text{InfoNCE}} = -\frac{1}{N} \sum_{i=1}^{N} \log \frac{\exp(\text{sim}(z_i, z_i^{+}) / \tau)}{\sum_{j=1}^{M} \exp(\text{sim}(z_i, z_j) / \tau)}$$
- 上式では、正例ペア $z_i, z_i^+$ の類似性を最大化。
- 負例は $j=1,…,Mj=1, …, Mj=1,…,M$に含まれる。
自己教師あり学習(SimCLR:対照損失:InfoNCE損失関数を使用)の実装
このコードはSimCLRモデルを使用して対照学習を行うためのものです。対照損失関数の一種であるInfoNCE損失関数を使用して、画像の異なるビュー間の類似度に基づいて特徴表現を学習します。
InfoNCE損失関数は、特にSimCLRや他のコントラスト学習フレームワークで広く使用されます。この損失関数は、正例(ポジティブペア)と負例(ネガティブペア)の類似度を比較することで、特徴表現を学習します。
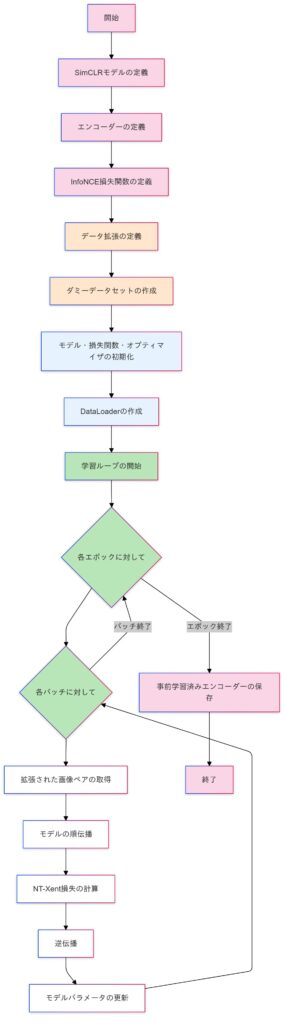
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import torchvision.transforms.functional as TF
import torchvision.transforms as transforms
# 1. SimCLRモデルの定義
class SimCLRModel(nn.Module):
def __init__(self, encoder, projection_dim):
super(SimCLRModel, self).__init__()
self.encoder = encoder
self.projection_head = nn.Sequential(
nn.Linear(encoder.output_dim, 512),
nn.ReLU(),
nn.Linear(512, projection_dim)
)
def forward(self, x):
h = self.encoder(x)
z = self.projection_head(h)
return h, z
# 2. エンコーダーの定義(例:ResNetを簡略化したもの)
class Encoder(nn.Module):
def __init__(self, input_channels, output_dim):
super(Encoder, self).__init__()
self.output_dim = output_dim
self.conv1 = nn.Conv2d(input_channels, 64, kernel_size=3, padding=1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(2)
self.flatten = nn.Flatten()
self.fc = nn.Linear(128 * 8 * 8, output_dim) # 入力サイズが 32x32 の場合
def forward(self, x):
x = self.pool1(self.relu1(self.conv1(x)))
x = self.pool2(self.relu2(self.conv2(x)))
x = self.flatten(x)
x = self.fc(x)
return x
# 3. InfoNCE損失関数の定義
class InfoNCELoss(nn.Module):
def __init__(self, temperature):
super(InfoNCELoss, self).__init__()
self.temperature = temperature
self.cosine_similarity = nn.CosineSimilarity(dim=1)
def forward(self, z_i, z_j):
"""
z_i: (batch_size, projection_dim)
z_j: (batch_size, projection_dim)
"""
batch_size = z_i.size(0)
# 類似度を計算
z = torch.cat((z_i, z_j), dim=0)
sim = self.cosine_similarity(z.unsqueeze(1), z.unsqueeze(0)) / self.temperature
# 正例のインデックス
sim_i_j = torch.diag(sim, batch_size)
sim_j_i = torch.diag(sim, -batch_size)
# 正例と負例を分ける
positive_samples = torch.cat((sim_i_j, sim_j_i), dim=0).reshape(batch_size * 2, 1)
mask = torch.ones((batch_size * 2, batch_size * 2), dtype=bool).fill_diagonal_(0)
negative_samples = sim[mask].reshape(batch_size * 2, -1)
# ラベルを作成
labels = torch.zeros(batch_size * 2).to(positive_samples.device).long()
# 損失を計算
logits = torch.cat((positive_samples, negative_samples), dim=1)
loss = nn.CrossEntropyLoss()(logits, labels)
return loss
# 6. 事前学習の実行
# ハイパーパラメータ
input_channels = 3
output_dim = 128
projection_dim = 64
temperature = 0.5
batch_size = 32
epochs = 10
lr = 0.001
# デバイスの設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# モデル、損失関数、オプティマイザの初期化
encoder = Encoder(input_channels, output_dim).to(device)
model = SimCLRModel(encoder, projection_dim).to(device)
criterion = InfoNCELoss(temperature).to(device)
optimizer = optim.Adam(model.parameters(), lr=lr)
# データローダーの作成
dataset = DummyDataset(transform=train_transform)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 事前学習ループ
for epoch in range(epochs):
for (img1, img2) in dataloader:
img1 = img1.to(device)
img2 = img2.to(device)
# 順伝播
_, z1 = model(img1)
_, z2 = model(img2)
# 損失の計算
loss = criterion(z1, z2)
# 逆伝播とパラメータの更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}/{epochs}, Loss: {loss.item():.4f}")
# 7. 事前学習済みエンコーダーの保存
torch.save(encoder.state_dict(), "pretrained_encoder.pth")
print("Pre-trained encoder saved to pretrained_encoder.pth")論文1:SimCLR『Chen, Ting, et al. “A Simple Framework for Contrastive Learning of Visual Representations.”』

- データ拡張の重要性
- SimCLRは、ランダムクロップや色の歪みなど、複数のデータ拡張を組み合わせることで、効果的な表現学習が可能になると示しました。特に、教師あり学習以上に強力なデータ拡張が学習の鍵となります。
- プロジェクションヘッドの導入
- SimCLRでは、非線形プロジェクションヘッドを追加することで、対照損失を適用する空間を最適化しました。これにより、表現の品質が大幅に向上することが確認されました。
- 教師あり学習を超える性能
- SimCLRはImageNetで76.5%のトップ1精度を達成し、教師ありのResNet-50に匹敵する性能を示しました。さらに、少量のラベルを使った微調整でも高い精度を維持し、転移学習でも優れた効果を発揮しています。
自己教師あり学習(対照損失:NT-Xent損失関数の場合)
SimCLRの締めくくりとして、先ほど紹介したInfoNCE損失は広範な対照学習で使用されているのですが、SimCLRに特化した設計のNT-Xent損失を紹介しておきます。
NT-Xent損失
$$\mathcal{L} = -\frac{1}{N} \sum_{i=1}^{N} \log \frac{\exp(\text{sim}(z_i, z_i^+) / \tau)}{\sum_{j=1}^{2N} \mathbb{1}_{[i \neq j]} \exp(\text{sim}(z_i, z_j) / \tau)}$$
- $z_i$,$z_i^+$:同じ画像から生成された2つのビューの埋め込み。
- $z_j$:他の埋め込み。
- sim($z_a,z_b$):コサイン類似度 $\text{sim}(z_a, z_b) = \frac{z_a \cdot z_b}{|z_a| |z_b|}$
- $τ$::温度スケールパラメータ。
- $N$:ミニバッチ内のサンプル数。
自己教師あり学習(SimCLR:対照損失:NT-Xent損失関数)の実装:
このコードは、自己教師あり学習の一種であるSimCLRを使用して、画像データに対する事前学習を行うためのものです。SimCLRは、画像の異なるビュー(変換されたバージョン)を使用して、類似度に基づいて特徴表現を学習します。以下に、コードの各部分が何をしているのかを簡単に説明します。
NT-Xent損失関数は、自己教師あり学習や表現学習において、データポイント間の類似度を学習するために使用されます。この損失関数は、正例(ポジティブペア)と負例(ネガティブペア)の類似度を比較することで、特徴表現を学習します。
ライブラリをインストール
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from PIL import Image
import torchvision.transforms.functional as TF
import torchvision.transforms as transformsSimCLRモデルの定義
class SimCLRModel(nn.Module):
def __init__(self, encoder, projection_dim):
super(SimCLRModel, self).__init__()
self.encoder = encoder
self.projection_head = nn.Sequential(
nn.Linear(encoder.output_dim, 512),
nn.ReLU(),
nn.Linear(512, projection_dim)
)
def forward(self, x):
h = self.encoder(x)
z = self.projection_head(h)
return h, z- 目的:SimCLRモデルを定義します。これは、エンコーダーとプロジェクションヘッドから構成されます。
- エンコーダー:入力画像を特徴ベクトルに変換します。
- プロジェクションヘッド:特徴ベクトルをさらに低次元の表現に変換します。
エンコーダーの定義
class Encoder(nn.Module):
def __init__(self, input_channels, output_dim):
super(Encoder, self).__init__()
self.output_dim = output_dim
self.conv1 = nn.Conv2d(input_channels, 64, kernel_size=3, padding=1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(2)
self.flatten = nn.Flatten()
self.fc = nn.Linear(128 * 8 * 8, output_dim) # 入力サイズが 32x32 の場合
def forward(self, x):
x = self.pool1(self.relu1(self.conv1(x)))
x = self.pool2(self.relu2(self.conv2(x)))
x = self.flatten(x)
x = self.fc(x)
return x- 目的:簡略化されたResNetのような構造を持つエンコーダーを定義します。
- 機能:入力画像を畳み込み層とプーリング層を通して特徴ベクトルに変換します。
NT-Xent損失関数の定義
class NTXentLoss(nn.Module):
def __init__(self, temperature, batch_size):
super(NTXentLoss, self).__init__()
self.temperature = temperature
self.batch_size = batch_size
self.cosine_similarity = nn.CosineSimilarity(dim=2)
self.criterion = nn.CrossEntropyLoss(reduction="sum")
def forward(self, z_i, z_j):
representations = torch.cat([z_i, z_j], dim=0)
similarity_matrix = self.cosine_similarity(representations.unsqueeze(1), representations.unsqueeze(0))
sim_ij = torch.diag(similarity_matrix, self.batch_size)
sim_ji = torch.diag(similarity_matrix, -self.batch_size)
positives = torch.cat([sim_ij, sim_ji], dim=0)
mask = (torch.ones_like(similarity_matrix) - torch.eye(2 * self.batch_size, device=similarity_matrix.device)).bool()
nominator = torch.exp(positives / self.temperature)
denominator = mask * torch.exp(similarity_matrix / self.temperature)
loss_partial = -torch.log(nominator / torch.sum(denominator, dim=1))
loss = torch.sum(loss_partial) / (2 * self.batch_size)
return loss- 目的:SimCLRで使用されるNT-Xent(Normalized Temperature-scaled Cross Entropy)損失関数を定義します。
- 機能:コサイン類似度を計算し、正例と負例の対数尤度を用いて損失を計算します。
データ拡張の定義
train_transform = transforms.Compose([
transforms.RandomResizedCrop(32),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4, hue=0.1),
transforms.RandomGrayscale(p=0.2),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])- 目的:データ拡張を定義します。
- 機能:画像に対してランダムリサイズクロップ、ランダム水平反転、カラージッター、ランダムグレースケール変換、テンソル変換、正規化を適用します。
ダミーデータセットの作成
class DummyDataset(Dataset):
def __init__(self, transform=None):
self.data = torch.randn(128, 3, 32, 32) # 128枚の 3x32x32 画像
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
img = self.data[idx]
if isinstance(img, torch.Tensor):
img = TF.to_pil_image(img)
if self.transform:
img1 = self.transform(img)
img2 = self.transform(img)
return img1, img2
return img, img- 目的:ダミーデータセットを定義します。
- 機能:各画像に対してデータ拡張を適用し、2つの異なるビューを生成します。
事前学習の実行
# ハイパーパラメータ
input_channels = 3
output_dim = 128
projection_dim = 64
temperature = 0.5
batch_size = 32
epochs = 10
lr = 0.001
# デバイスの設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# モデル、損失関数、オプティマイザの初期化
encoder = Encoder(input_channels, output_dim).to(device)
model = SimCLRModel(encoder, projection_dim).to(device)
criterion = NTXentLoss(temperature, batch_size).to(device)
optimizer = optim.Adam(model.parameters(), lr=lr)
# データローダーの作成
dataset = DummyDataset(transform=train_transform)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 事前学習ループ
for epoch in range(epochs):
for (img1, img2) in dataloader:
img1 = img1.to(device)
img2 = img2.to(device)
# 順伝播
_, z1 = model(img1)
_, z2 = model(img2)
# 損失の計算
loss = criterion(z1, z2)
# 逆伝播とパラメータの更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}/{epochs}, Loss: {loss.item():.4f}")- 目的:SimCLRモデルを使用して事前学習を行います。
- 機能:各エポックで画像ペアをモデルに入力し、損失を計算してモデルのパラメータを更新します。
事前学習済みエンコーダーの保存
torch.save(encoder.state_dict(), "pretrained_encoder.pth")
print("Pre-trained encoder saved to pretrained_encoder.pth")- 目的:事前学習済みのエンコーダーの重みを保存します。
InfoNCE損失とNT-Xent損失の違い
| 特徴 | NT-Xent損失 | InfoNCE損失 |
|---|---|---|
| 目的 | SimCLRに特化した設計。 | 広範な対比学習で使用。 |
| 負例の取り扱い | ミニバッチ内での負例が明確に定義される。 | 負例の範囲がタスクに応じて柔軟に変化。 |
| 温度スケール | 温度パラメータ($τ$)を強調し、SimCLRの重要な要素としている。 | 温度パラメータを使用するが、特定の強調はない。 |
NT-Xent損失とInfoNCE損失は数学的には非常に似ていますが、NT-Xent損失はInfoNCE損失の特化型と言えます。SimCLRの文脈では、NT-Xent損失を使用するのが適切であり、他のタスクや一般的な対比学習ではInfoNCE損失が使用されることが多いです。
論文2:BYOL『Grill, Jean-Bastien, et al. “Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning.”』

- 負のペア不要の自己教師付き学習法を提案
- BYOLは、負のペアや大規模なバッチサイズを必要とせず、自己教師付き学習を実現する革新的な手法です。ターゲットネットワークとオンラインネットワークが互いに学習し合うことで、効率的かつ高品質な表現を学習します。
- ImageNetでの最先端性能
- BYOLは、ResNet-50を用いたImageNetの線形評価で74.3%のトップ1精度を達成しました。これは従来の自己教師付き学習手法を大幅に上回る性能で、幅広い応用にも適した強力なモデルです。
- 汎用性と転移性能の高さ
- BYOLは、物体検出やセマンティックセグメンテーションなど多様なタスクに対応可能です。CIFARやVOCといったデータセットでも高い転移性能を発揮し、自己教師付き学習の新たな基盤として注目されています。
論文3:『MoCo:He, Kaiming, et al. “Momentum Contrast for Unsupervised Visual Representation Learning.”』

- MoCo の提案
- MoCoは、動的な辞書とモーメンタム更新を組み合わせた新しいコントラスト学習手法です。これにより、大量のネガティブペアを効率的に活用し、自己教師あり学習を安定して実現しました。
- 大規模データにおける効率性と性能向上
- MoCoは、ImageNetの線形分類で優れた性能を発揮し、物体検出やセグメンテーションなどの転移タスクでも従来の教師あり学習を上回る成果を示しました。そのスケーラビリティの高さも大きな特徴です。
- 他手法との差別化と汎用性
- MoCoは、SimCLRのように大規模なバッチサイズや複雑なデータ拡張を必要とせず、効率的に辞書を構築できます。多様な視覚タスクに応用可能で、自己教師あり学習の新しい基盤を提供しています。
ファインチューニングに関連する派生手法
ファインチューニングは、既存の学習済みモデル(事前学習モデル)を新たなタスクに適応させるため、モデル全体または一部の層を微調整する手法です。転移学習の主要な方法の一つであり、計算リソースやデータが限られる場合でも高精度なモデル構築が可能です。ただし、過学習のリスクやハイパーパラメータの調整が必要となる点には注意が必要です。
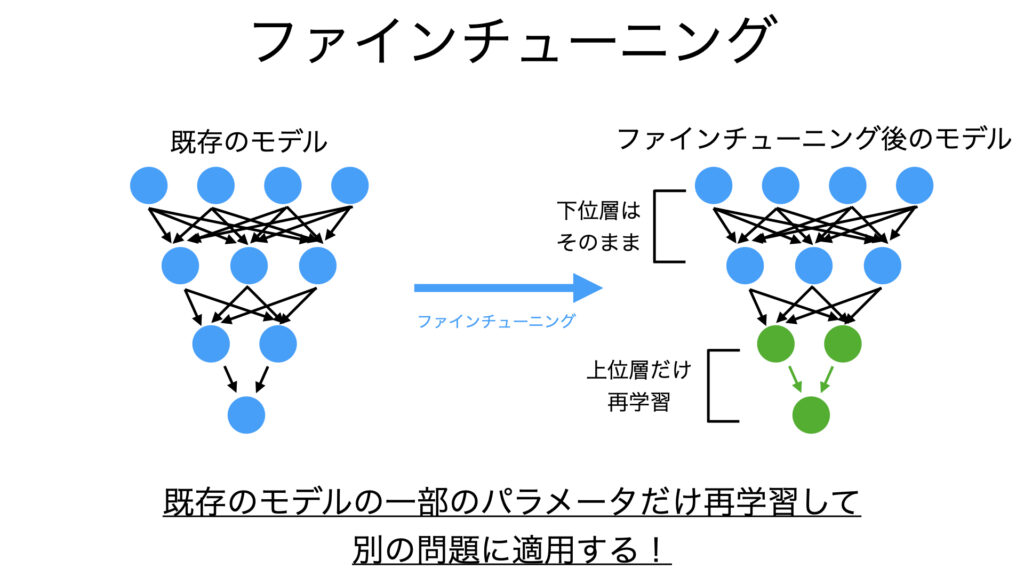
概要と特徴:
Fine-Tuningは、事前学習済みの重みを初期値として用い、新しいタスクのデータでモデルを再学習させるプロセスを指します。
- 新しいデータセットのサイズが小さい場合でも、事前学習済みの特徴を活用できる。
- モデル全体を再学習する場合と、特定の層だけを学習する場合がある(部分凍結)。
- 学習率や初期化方法の調整が重要。
数式:
$$\theta^* = \underset{\theta}{\arg\min} \mathcal{L}(f_{\theta}(X), y)
$$
- $θ$:学習済みモデルの重み。
- $f_θ{(X)}$:入力 $X$ に対するモデルの出力。
- $y$:真のラベル。
- $L$:損失関数(例: クロスエントロピー損失)。
Fine-Tuningでは、事前学習済みの重み $\theta_{\text{pretrained}}$ を初期値として用い、特定のタスク用に $\theta$ を最適化します。
注意点:
- 事前学習済みモデルと新しいタスクで、入力データの形式や出力の形式が異なる場合は、モデルの一部を変更(例えば、出力層のニューロン数を変更)する必要があります。
- 事前学習済みモデルのどの層を再学習するか、どの層を凍結(重みを固定)するかは、タスクの類似性やデータセットのサイズなどを考慮して決定する必要があります。
目的と課題
| 目的 | 説明 |
|---|---|
| 新しいタスクへの適応 | 既存モデルの一般的な特徴表現を活用し、特定のタスクに適応させる。 |
| データ不足の補完 | 小規模データセットでも高いパフォーマンスを実現する。 |
| 計算コストの削減 | モデルをゼロから学習する必要がなく、効率的な学習を可能にする。 |
| 課題 | 説明 |
|---|---|
| 過学習 | 小規模データでFine-Tuningを行うと、モデルが訓練データに過度に適応し、汎化性能が低下するリスクがある。 |
| 転移先タスクとのギャップ | 事前学習のデータ分布と新しいタスクのデータ分布が大きく異なる場合、モデルの性能が低下する可能性がある。 |
| ハイパーパラメータ調整の複雑さ | 層の凍結・解凍、学習率スケジュールなどの設定が複雑で、適切な調整が求められる。 |
メリットとデメリット
| メリット | デメリット |
|---|---|
| 高速学習:既存の重みを活用するため、学習が早く収束します。 | 依存性の高い初期化:事前学習モデルの性能が転移先タスクの精度に大きな影響を与えます。 |
| 高い精度:大規模データセットで学習された特徴表現を再利用できます。 | データセットの不整合:タスク間でデータ分布が異なるときに精度が低下します。 |
| リソースの節約:データや計算資源が限られた環境でも使用可能です。 | 複雑なチューニング:凍結層や学習率の選択が結果に大きく影響します。 |
適用例:
| 適用分野 | 具体例 |
|---|---|
| 画像認識 | ImageNetで事前学習されたモデルを、特定の画像分類タスクに適用。 |
| 自然言語処理 | BERTやGPTなどの言語モデルを、感情分析や質問応答などの特定タスクにファインチューニング。 |
| 医用画像解析 | 一般的な画像データで学習したモデルを、特定の病変検出タスクに適用。 |
事前学習済みモデルの層を凍結する理由
- 特徴抽出器としての利用
- 事前学習済みモデルの畳み込み層は、一般的な特徴を抽出する能力を持っています。これらの層を凍結することで、これまでに学習した特徴を保持し、新しいタスクに適応させることができます。
- 計算コストの削減
- 凍結された層は更新されないため、計算コストが削減され、トレーニングが高速化されます。
- 過学習の防止
- 全結合層のみを学習対象とすることで、過学習のリスクを減らし、新しいタスクに対してより良い一般化性能を得ることができます。
ファインチューニングの実装例:
このコードは、事前学習済みのResNet50モデルを使用して新しいタスクに対してファインチューニングを行う簡単な方法を示しています。全結合層を新しいタスクに適応させ、全結合層のみを学習対象としてトレーニングします。これにより、事前学習済みモデルの特徴抽出能力を活用しつつ、新しいタスクに適応させることができます。
import torch
import torch.nn as nn
from torchvision import models, datasets, transforms
from torch.utils.data import DataLoader
# 事前学習済みモデルのロード
model = models.resnet50(pretrained=True)
# 全結合層を新しいタスクに適応
num_classes = 10 # 新しいタスクのクラス数
model.fc = nn.Linear(model.fc.in_features, num_classes)
# 層を凍結する例(特徴抽出器として使用)
for param in model.parameters():
param.requires_grad = False
# 全結合層のみを学習対象に
for param in model.fc.parameters():
param.requires_grad = True
# モデルのトレーニング設定
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.fc.parameters(), lr=0.001)
# データセットとデータローダーの定義
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
train_dataset = datasets.FakeData(transform=transform) # ダミーデータセットを使用
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 学習ループ
num_epochs = 5
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
# 順伝播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 逆伝播とパラメータの更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(train_loader.dataset)
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {epoch_loss:.4f}")
print("Training complete")論文1:『Donahue, J., Jia, Y., Vinyals, O., Hoffman, J., Zhang, N., Tzeng, E., & Darrell, T. (2014). Decaf: A deep convolutional activation feature for generic visual recognition.』
- 事前学習済みCNNの特徴量を転移学習に利用する効果を実証的に示した初期の重要な論文。

- ファインチューニングの重要性
- DeCAFは、事前学習済みモデルの特徴を活用しつつ、特定のタスクに適応させるファインチューニングの重要性を示しています。事前学習モデルは汎用的な特徴を持ち一定の性能を発揮しますが、新しいタスクでは特定の特徴を学習する必要があります。ファインチューニングにより、汎用性とタスク適応性を両立させたモデルを構築でき、特に複雑なタスクやデータ分布の異なる状況で高い性能を実現します。
- 転移学習の向上効果
- ファインチューニングを通じて、事前学習済みモデルの汎用的な特徴を強化し、特定のタスクに適応させることで、より高い性能を引き出せることが確認されています。特にドメイン適応タスクでは、新しいデータ分布に対応する必要があるため、ファインチューニングが有効であり、事前学習特徴の直接利用を上回る精度向上が得られます。
- 効率性と汎用性
- ファインチューニングは、少量の追加データで事前学習済みモデルを新しいタスクに効率的に適応させる方法です。汎用的な特徴を活かすことで、異なるデータセット間でも高性能を実現し、大量データが不要な状況や多様なタスクにおいて特に有効です。
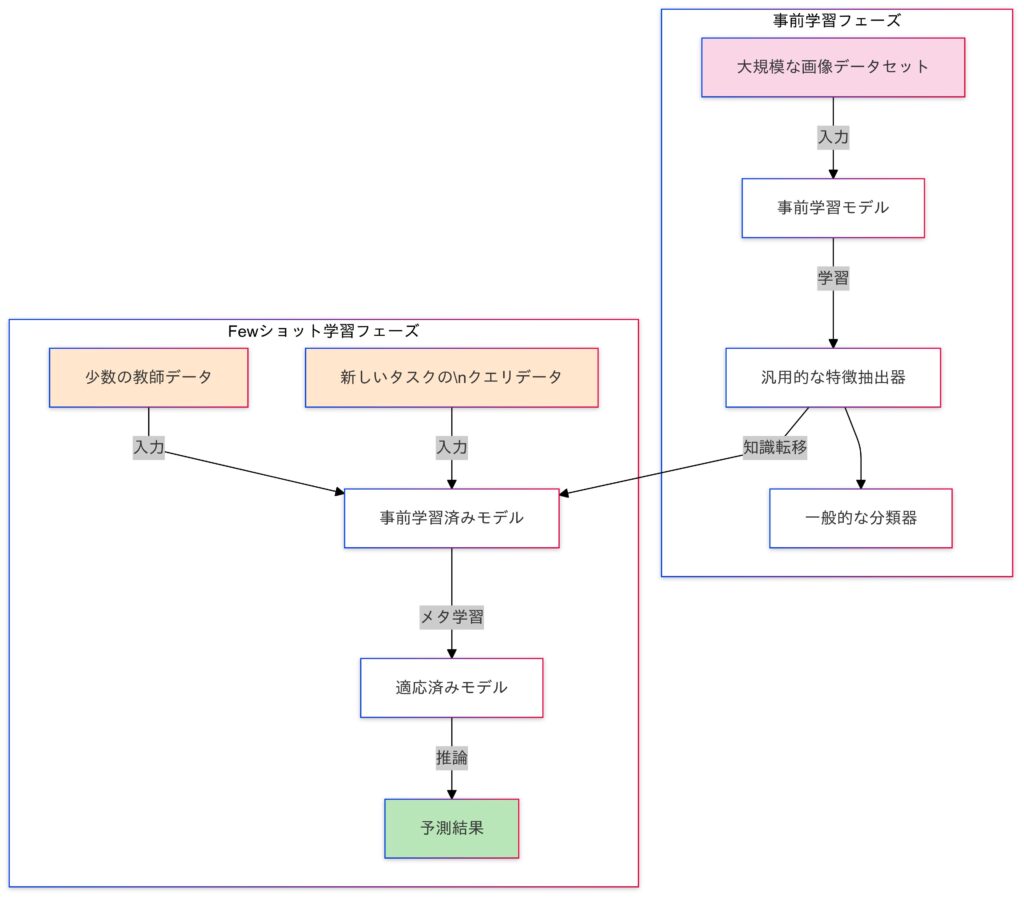
Zero-Shot Transfer / Few-Shot Transfer
Zero-Shot Transferは、事前学習済みモデルを新しいタスクに適用する際、追加のラベル付きデータを使用せずに対応する手法です。一方、Few-Shot Transferは、少量のラベル付きデータを用いてモデルを新タスクに適応させる方法です。これらの手法は、特にデータが限られている状況で有効であり、適切に活用することで高いパフォーマンスを実現できます。
Zero-Shot Transfer
- モデルが全く見たことのないタスクやクラスに対して、ラベル付きデータを使用せずに直接予測を行う。
- 例:CLIP(画像とテキストのペアを用いた事前学習)。
- Zero-Shot学習では、モデルが未学習の新しいタスクやクラスに対応する必要があります。そのため、事前学習で得た知識を新たな状況に適用する能力、すなわち一般化性能が重要となります。モデルの性能は、この一般化能力に大きく依存します。
Few-Shot Transfer
- 新しいタスクに少量のラベル付きデータを使用して、モデルを微調整し、適応させる。
- 例:Meta-learning(MAMLなど)。
- メタ学習との関連
- 多くの場合、「学習の仕方を学習する」メタ学習 (Meta-Learning) の枠組みで研究されます。
- Few-Shot学習は、少量のデータからモデルを新しいタスクに適応させる手法です。事前学習で得た知識を活用し、データが少ない状況でも高い性能を発揮します。これにより、データ収集が困難なタスクでも効率的な学習が可能となります。
数式による表現
Zero-Shot Transfer
- Zero-Shot Transferでは、タスクを説明する情報(例:属性、クラスの説明文)を用いて、見たことのないクラスへの分類を行います。
$$\hat{y} = \underset{y \in Y}{\arg\max} f_{\theta}(x, y’)$$
- $f_θ$:モデルの出力(例: CLIPでは画像とテキストの類似度スコア)。
- $Y$:タスクのラベル集合。
Few-Shot Transfer
- MAMLの目標は、新しいタスクに少量のデータ(Few-Shot)で適応できるようなモデルパラメータ $θ$ を学習することです。
内部更新(タスク固有の更新)
- 個々のタスクで適応
$$\theta’ = \theta – \alpha \nabla_{\theta} L_T$$
この式は、新しいタスク $T$ に対するパラメータ $θ$ の微調整(タスク固有の最適化)を示しています。
- Few-Shot Learningでは、少量のタスクデータ(サポートセット)を使用してモデルを迅速に適応させる必要があります。
- この適応は、初期パラメータ $\theta$ を基に、損失 $L_T$ の勾配 $\nabla_\theta L_T$ を計算し、ステップサイズ $\alpha$ に従って更新することで実現します。
メタ更新(初期パラメータの更新)
メタタスクの損失最小化
$$\theta^* = \arg\min_{\theta} \sum_{T_i \in T} L_{T_i} (g\theta – \alpha \nabla_{\theta} L_{T_i})$$
- $T_i$:タスク集合。$L$:損失関数。$α$:学習率。
- $g\theta – \alpha \nabla_{\theta} L_{T_i}$:各タスク $T_i$ における、パラメータ $θ$ を微調整(Fine-Tuning)した後のモデルの出力です。
この式は、複数のタスク($T_i$)に対するメタ損失を最小化することを示しています。
- 初期パラメータ $\theta$ が、新しいタスクに迅速に適応できるように設計されています。
- 各タスク $T_i$ に対して内部更新を行い、微調整後のパラメータ $\theta’$ を用いてタスク固有の損失を評価します。
- この損失を全タスクにわたって最小化することで、汎用的な初期パラメータ $\theta^*$ を得ることを目指します。
目的と課題
| 目的 | 課題 |
|---|---|
| データ制限への対応 | タスク間の分布の違い: Zero-Shotでは分布が大きく異なると精度が低下する。 |
| ラベル付きデータが少ない場面でのタスク適応 | データのラベル不足: Few-Shotでは少量のデータから十分な情報を学習する必要がある。 |
| 汎用性の確保: 事前学習モデルを多種多様なタスクで活用 | 計算コスト: Few-Shotではメタラーニングに膨大な計算資源が必要。 |
メリットとデメリット
| メリット | デメリット |
|---|---|
| データ収集のコスト削減:大量のラベル付きデータを必要としないため、データ収集のコストを大幅に削減できる。 | 性能の限界:教師あり学習と比較して、精度が劣る場合がある。特にゼロショット学習では、その傾向が顕著。 |
| 迅速なプロトタイピング:新しいタスクに対するモデルを迅速にプロトタイピングし、検証することができる。 | タスク記述への依存:ゼロショット学習では、タスクやクラスを記述する情報(属性、説明文など)が必要となる。 |
| レアクラスへの対応:データがほとんど、または全く存在しないようなレアなクラスにも対応できる。 | ドメイン依存性:事前学習された知識が特定のドメインに偏っている場合、他のドメインへの転移が難しい。 |
| 継続的な学習への応用:新しいクラスやタスクが継続的に追加されるような状況において、効率的に学習を続けることができる。 | ハイパーパラメータの調整:メタ学習などの枠組みを用いる場合、ハイパーパラメータの調整が難しい場合がある。 |
適用例
- 画像分類
- Zero-Shot:見たことのない動物の画像を、その動物の説明文や属性情報を用いて分類する。
- Few-Shot:数枚の画像から、新しい種類の花を分類する。
- 物体検出
- Zero-Shot:新しい種類の物体を、その物体のテキスト記述から検出する。
- Few-Shot:数個のバウンディングボックス例から、新しいカテゴリの物体を検出する。
- 自然言語処理
- Zero-Shot:見たことのない単語の意味を、その単語の定義文から推測する。
- Few-Shot:数個の例文から、新しい感情を分類する。
- ロボティクス
- Zero-Shot:新しいタスクを、そのタスクのテキスト記述から実行する。
- Few-Shot:数回のデモンストレーションから、新しい動作を学習する。
- 医用画像診断
- Few-Shot:数例の症例から、新しい疾患を診断する。
Zero-Shot Transferの実装例:
このコードは、CLIPモデルを使用してZero-Shot Transferを実行する方法を示しています。事前学習済みのCLIPモデルを使用して、テキストと画像の類似度を計算し、画像がどのテキストに最も近いかを判定します。これにより、事前学習済みのモデルを使用して新しいタスクに対してゼロショットで適応することができます。
モデルとプロセッサのロード
from transformers import CLIPProcessor, CLIPModel
import torch
from PIL import Image
# モデルとプロセッサのロード
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")CLIPModelとCLIPProcessorをロードします。これらはHugging FaceのTransformersライブラリから提供されています。
入力データ
texts = ["a photo of a cat", "a photo of a dog"]Zero-Shot Transferのためのテキストラベルを定義します。
画像の読み込みと前処理
image_pathに猫か犬の画像ファイルパスを指定して下さい。
image_path = "path_to_your_image.jpg" # ここに画像ファイルのパスを指定
image = Image.open(image_path)画像を読み込みます。ここではPILライブラリを使用しています。
テキストと画像をプロセッサに渡してテンソルに変換
inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)テキストと画像をプロセッサに渡し、テンソルに変換します。
モデルの推論
with torch.no_grad():
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # 画像ごとのスコア
probs = logits_per_image.softmax(dim=1) # 確率モデルを使用して推論を行い、画像ごとのスコアを取得します。次に、ソフトマックス関数を適用して確率を計算します。
結果の表示
print("Logits per image:", logits_per_image)
print("Probabilities:", probs)画像ごとのスコアと確率を表示します。
出力
Logits per image: tensor([[19.9333, 27.6718]])
Probabilities: tensor([[4.3553e-04, 9.9956e-01]])画像に対する各テキストのスコア(ロジット)は、そのテキストが画像に適合する度合いを示し、例では「a photo of a dog」のスコア27.6718が「a photo of a cat」の19.9333より適合性が高いと判断されています。
ロジットにソフトマックス関数を適用して得られた確率は、テキストが画像に適合する度合いを示し、例では「a photo of a dog」の確率が0.99956(約99.96%)と「a photo of a cat」の0.00043553(約0.04%)より適合性が高いと判断されています。
全体のコード
from transformers import CLIPProcessor, CLIPModel
import torch
from PIL import Image
# モデルとプロセッサのロード
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# 入力データ
texts = ["a photo of a cat", "a photo of a dog"]
# 画像の読み込みと前処理
image_path = "/Users/yoshihisashinzaki/Desktop/Python/env/DALL·E 2024-12-31 21.29.06 - A realistic photograph of a Labrador Retriever sitting outdoors in a grassy park, with a happy and friendly expression, well-groomed fur, and vibrant .webp" # ここに画像ファイルのパスを指定
image = Image.open(image_path)
# テキストと画像をプロセッサに渡してテンソルに変換
inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
# モデルの推論
with torch.no_grad():
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # 画像ごとのスコア
probs = logits_per_image.softmax(dim=1) # 確率
# 結果の表示
print("Logits per image:", logits_per_image)
print("Probabilities:", probs)Few-Shot Transferの実装例:
次はFew-Shot Transferの実装例を紹介する前にメタ学習についての説明をしておきます。
メタラーニングは、「学習の学習」として、新しいタスクに迅速に適応する能力をモデルに付与する方法です。MAMLのような手法を使用することで、モデルは少量のデータや少数のトレーニングステップで新しいタスクに対して高いパフォーマンスを発揮することができます。メタラーニングのプロセスには、各タスクごとの内部更新と、全体のメタモデルを更新する外部更新が含まれます。
- メタ学習とは?
- メタラーニングは、通常の機械学習とは異なり、複数のタスクを通じてモデルをトレーニングします。各タスクは、モデルが新しいタスクに迅速に適応するための「学習エピソード」として扱われます。
- メタ学習のプロセス
- タスクのセットアップ
- メタラーニングでは、複数のタスクが用意されます。各タスクは、独自のデータセットを持ちます。
- 内部更新(Inner Update)
- 各タスクに対して、モデルのコピーを作成し、そのタスクのデータセットを使用して数ステップだけトレーニングします。このプロセスは、通常の勾配降下法(SGDなど)を使用して行われます。
- 外部更新(Outer Update)
- 全てのタスクに対して内部更新を行った後、各タスクの損失を合計してメタ損失を計算します。このメタ損失を使用して、メタモデルのパラメータを更新します。このプロセスは、適応的な学習率を持つオプティマイザ(Adamなど)を使用して行われます。
- タスクのセットアップ
次のコードは、MAMLを使用してFew-Shot Transferを実行する簡易実装例です。シンプルな線形モデルを使用し、メタ学習プロセスを通じて新しいタスクに対して迅速に適応する方法を示しています。
import torch
import torch.nn as nn
import torch.optim as optim
# モデル定義
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)メタラーニングプロセスの設定
model = SimpleModel()
meta_optimizer = optim.Adam(model.parameters(), lr=0.001)
loss_fn = nn.MSELoss()メタラーニングのハイパーパラメータ
meta_lr = 0.001 # メタ学習率
inner_lr = 0.01 # 内部学習率
num_inner_steps = 5 # 内部更新ステップ数メタラーニングと内部更新の学習率、および内部更新のステップ数を設定します。
タスクセットの定義
task_set = [
(torch.randn(10, 10), torch.randn(10, 1)), # ダミーデータ
(torch.randn(10, 10), torch.randn(10, 1)), # ダミーデータ
# 他のタスクデータを追加
]タスクセットを定義します。ここではダミーデータを使用していますが、実際のタスクデータに置き換えることができます。
メタラーニングループ
for epoch in range(100): # メタエポック数
meta_optimizer.zero_grad()
meta_loss = 0.0
for task_data in task_set:
x, y = task_data # タスクデータ
# モデルのコピーを作成してタスクごとに更新
task_model = SimpleModel()
task_model.load_state_dict(model.state_dict())
task_optimizer = optim.SGD(task_model.parameters(), lr=inner_lr)
# 内部ループ(タスクごとの更新)
for _ in range(num_inner_steps):
task_optimizer.zero_grad()
task_loss = loss_fn(task_model(x), y)
task_loss.backward()
task_optimizer.step()
# メタ損失の計算
meta_loss += loss_fn(task_model(x), y)
# メタ損失の逆伝播と更新
meta_loss.backward()
meta_optimizer.step()
print(f"Epoch {epoch+1}, Meta Loss: {meta_loss.item():.4f}")
print("Meta-learning complete")メタ学習ループを実行し、各エポックでタスクごとにモデルを更新します。内部ループでは、各タスクに対してモデルのコピーを作成し、タスクごとに更新を行います。メタ損失を計算し、メタオプティマイザを使用してモデルを更新します。
Meta Lossの意味
print(f"Epoch {epoch+1}, Meta Loss: {meta_loss.item():.4f}")出力:
Epoch 98, Meta Loss: 1.7553
Epoch 99, Meta Loss: 1.7553
Epoch 100, Meta Loss: 1.7553Meta Lossは、各エポックで全てのタスクに対して計算された損失の合計を示しており、メタ学習プロセス全体のパフォーマンスを評価するための指標です。
全体のコード
import torch
import torch.nn as nn
import torch.optim as optim
# モデル定義
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
# メタラーニングプロセスの設定
model = SimpleModel()
meta_optimizer = optim.Adam(model.parameters(), lr=0.001)
loss_fn = nn.MSELoss()
# メタラーニングのハイパーパラメータ
meta_lr = 0.001 # メタ学習率
inner_lr = 0.01 # 内部学習率
num_inner_steps = 5 # 内部更新ステップ数
# タスクセット T_i(ダミーデータを使用)
task_set = [
(torch.randn(10, 10), torch.randn(10, 1)), # ダミーデータ
(torch.randn(10, 10), torch.randn(10, 1)), # ダミーデータ
# 他のタスクデータを追加
]
# メタラーニングループ
for epoch in range(100): # メタエポック数
meta_optimizer.zero_grad()
meta_loss = 0.0
for task_data in task_set:
x, y = task_data # タスクデータ
# モデルのコピーを作成してタスクごとに更新
task_model = SimpleModel()
task_model.load_state_dict(model.state_dict())
task_optimizer = optim.SGD(task_model.parameters(), lr=inner_lr)
# 内部ループ(タスクごとの更新)
for _ in range(num_inner_steps):
task_optimizer.zero_grad()
task_loss = loss_fn(task_model(x), y)
task_loss.backward()
task_optimizer.step()
# メタ損失の計算
meta_loss += loss_fn(task_model(x), y)
# メタ損失の逆伝播と更新
meta_loss.backward()
meta_optimizer.step()
print(f"Epoch {epoch+1}, Meta Loss: {meta_loss.item():.4f}")
print("Meta-learning complete")論文1:『Learning Transferable Visual Models From Natural Language Supervision』
- Zero-Shot Transfer

- 高い汎用性
- CLIPは、事前学習で見たことがないタスクやデータセットに対しても、新しいラベル付けを必要とせず予測を行えるゼロショット学習が可能です。この特性により、多様な用途で柔軟に活用できます。
- ゼロショット適応
- CLIPは、事前学習で学んだ画像と言葉の関係を活用することで、新しいデータセットに対しても特定のラベルを準備する必要がありません。自然言語でラベルの候補を入力するだけで、それに最も一致するものを選んで予測ができます。
- 多様なデータセットでの成功例
- CLIPは、Flickr30kやMS-COCOといった特徴の異なるデータセットでも、事前学習で見たことのないクラスを高い精度で分類でき、その汎用性が幅広い分野で有効であることを示しています。
論文2:『Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks』
- Few-Shot Transfer

- 汎用性の高いアプローチ
- MAMLは、分類、回帰、強化学習といった多様なタスクに対応できる柔軟なメタラーニング手法です。勾配降下法を利用するモデルであれば特定のアーキテクチャを問わず適用可能で、タスクを「学習の単位」として扱うため、新しいタスクにも少量のデータと数回の勾配更新で迅速に適応できます。また、パラメータを最適な初期状態に設定することで、追加の設計や調整を必要とせず幅広い応用が可能です。
- 最適な初期化による迅速な適応
- MAMLは、モデルのパラメータを新しいタスクに迅速に適応できる初期状態に最適化する手法です。この最適化により、1ショットや5ショット学習のような少数のデータポイントでも、数回の勾配降下ステップで高性能を実現します。学習済みのモデルはタスク固有のデータに敏感に反応するため、最小限のトレーニングデータで汎化性能を発揮できます。これにより、従来の手法と比べ、少数ショット学習での適応速度と精度が大幅に向上します。
- 従来手法を超える性能
- MAMLは、OmniglotやMiniImagenetといったベンチマークで、Matching NetworksやSiamese Networksなどの従来手法を上回る精度を達成しました。特に1ショット・5ショット学習において優れた性能を示し、Few-Shot学習における新たな基準を確立しました。MAMLはパラメータの初期化を最適化することで、少数のデータと簡単な勾配更新で迅速に適応可能です。このシンプルさと汎用性により、従来手法よりも効率的かつ柔軟に少数ショットタスクに対応できるのが特徴です。
論文3:『Language Models are Few-Shot Learners』

- モデルの規模とFew-Shot性能
- GPT-3は、1750億パラメータを持つ大規模な言語モデルで、これにより特定タスクのデータを用いた微調整を必要とせず、高度なFew-Shot学習性能を実現しました。Few-Shot学習とは、少数の例だけで新しいタスクに適応する能力を指し、文法訂正や翻訳、質問応答など多様なタスクに対応可能です。この柔軟性により、従来のモデルを超える適応力と実用性を示し、自然言語処理の新たな可能性を切り開きました。
- 汎用性と適応性
- GPT-3は、新しいタスクに対し、特定のデータセットや微調整なしで、少ない例や簡単な指示のみで高いパフォーマンスを発揮します。文法訂正や質問応答、抽象的な概念生成など、多様なタスクに柔軟に対応可能で、タスク固有データの準備が難しい場面でも有用性を発揮します。人間が少ない例で新しい作業を理解するように、GPT-3も迅速に適応し、教育やビジネスなどさまざまな分野で幅広い応用可能性を示しています。
- 課題と倫理的問題
- GPT-3は、学習データに由来するバイアスや誤用のリスクといった課題を抱えています。偏りが出力に影響を与える可能性や、偽情報拡散や悪意ある利用への懸念が指摘されています。また、一部の複雑なタスクでは性能の限界も見られます。これらの課題に対し、バイアス軽減や利用制限の強化、効率化の取り組みが進められており、今後、安全で公平なAI活用が期待されています。倫理的問題への対応は、責任あるAI利用の鍵となります。
ファインチューニングとの共通点と違い
ゼロショットはファインチューニングを必要とせず、Fewショットは場合によってファインチューニングと見なされることもありますが、どちらも転移学習の一部であり、応用分野やデータの制約に応じて適切な手法を選ぶことが重要です。
| 特徴 | ゼロショット | Fewショット | ファインチューニング |
|---|---|---|---|
| 事前学習の利用 | 必須 | 必須 | 必須 |
| 追加の学習 | 不要(事前学習のみで対応) | 必要(少量のデータで調整) | 必要(十分なデータで調整) |
| 必要なデータ量 | なし | 少数 | 多い |
| 主な用途 | タスク汎化能力の評価 | データ不足時の新タスク適応 | 新タスクへの最適化 |
| モデルの改変 | 微調整なし | 少量データで微調整 | 大幅な微調整が可能 |
Feature Extraction
概要と特徴
Feature Extraction(特徴抽出)は、事前学習済みモデルの初期層を固定し、その層を新しいタスク向けの特徴抽出器として活用する手法です。この方法では、事前学習で得られた一般的な特徴(エッジ、テクスチャ、形状など)を再利用し、効率的に新しいタスクに適応できます。
転移学習における事前学習フェーズとドメイン適応フェーズと特徴抽出フェーズのイメージ
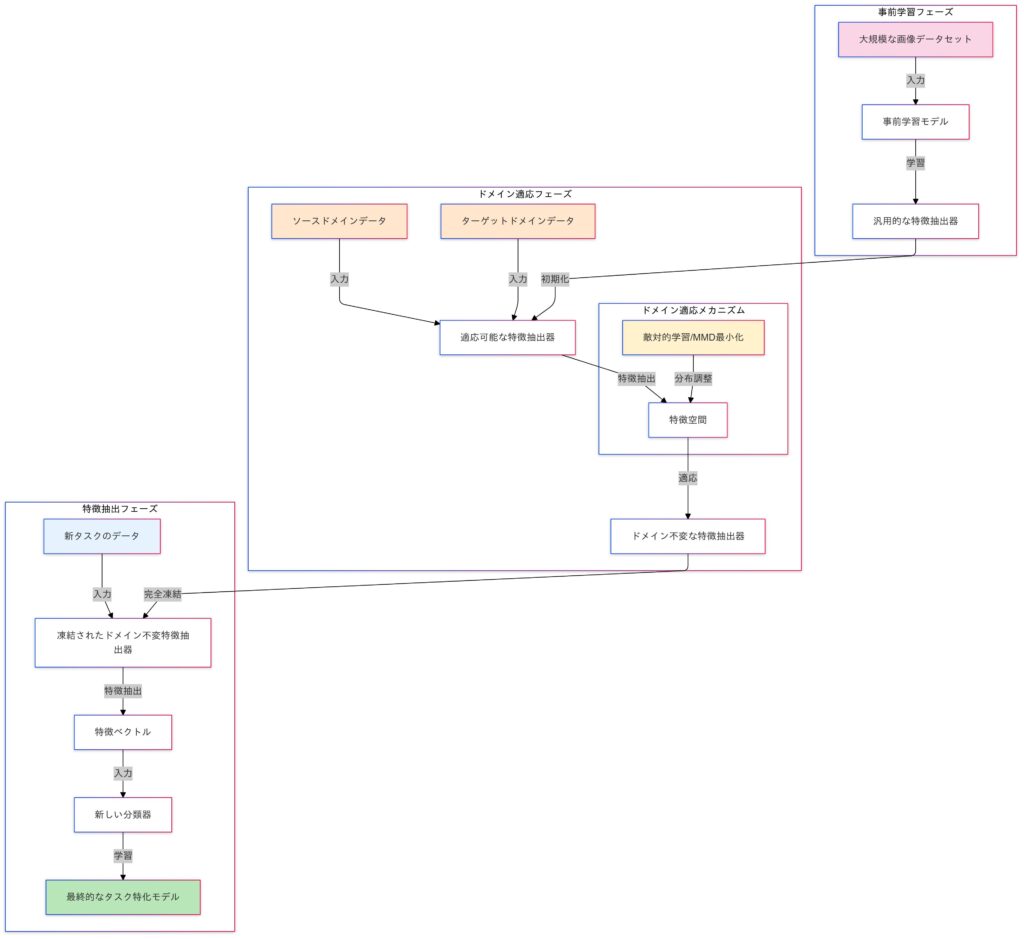
数式
入力データ $x$ に対して、特徴抽出器として事前学習モデルの初期層 $f_{\theta}$ を適用し、特徴ベクトル $h$ を生成します。
- $h=fθ(x)$, $θ$ は固定された事前学習済みモデルのパラメータ
その後、この特徴ベクトル $h$ を用いて新しいタスクの分類器や予測器 $g_{\phi}$ に入力します。$\hat{y} = g_{\phi}(h)$, $ϕ$ は新しいタスクに応じて学習されるパラメータ
目的
- 計算コスト削減
- 事前学習済みモデルのパラメータを固定し、微調整を行わないことで計算リソースを節約。
- 汎化性能の向上
- 事前学習済みモデルの一般的な特徴を活用し、新しいタスクに適応。
- 少量データ対応
- データが限られている場合でも有効な学習が可能。
注意点
- タスク間の相違
- 事前学習のドメインと新しいタスクのドメインが大きく異なる場合、性能が低下する可能性。
- 表現力の制限
- 特徴抽出器として固定された層は、タスク固有の特徴を十分に学習できない場合がある。
メリットとデメリット
| メリット | デメリット |
|---|---|
| 計算効率: パラメータ更新が不要なため、トレーニングが高速。 | タスク適応の制限: 特定のタスクで微調整が必要な場合、性能が劣る可能性。 |
| 少量データでの利用: 微調整を行わないため、オーバーフィッティングのリスクが低い。 | 汎化性能の限界: 新しいタスクが事前学習モデルの一般的特徴に依存しない場合、効果が限定的。 |
| モデル再利用: 同じ事前学習済みモデルを異なるタスクで繰り返し利用可能。 |
適用例
| 適用分野 | 適用例 |
|---|---|
| 医療画像解析 | ImageNetで事前学習したモデルを用い、医療画像(例: MRI、CT)から特徴を抽出して分類。 |
| 自然言語処理 | BERTのエンコーダ層を固定し、文章特徴ベクトルを生成し、テキスト分類タスクに使用。 |
| 音声処理 | 音声波形から特徴を抽出し、キーワードスポッティングや音声認識に応用。 |
Feature Extractionの実装例:
このコードは、LSTMモデルを使用して金融の時系列データを分類するための簡単な例を示しています。LSTMモデルを使用して、時系列データから特徴を抽出し、分類タスクを実行します。これにより、金融データの予測や分類の基本的な流れを理解することができます。
ライブラリのインポート
import torch
import torch.nn as nn
import torch.optim as optimLSTMモデルの定義
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
out, _ = self.lstm(x, (h0, c0))
out = self.fc(out[:, -1, :])
return outLSTMModelクラスは、LSTM層と全結合層を持つモデルを定義します。forwardメソッドでは、初期の隠れ状態とセル状態をゼロで初期化し、LSTM層を通過させた後、最後のタイムステップの出力を全結合層に入力します。
ハイパーパラメータの設定
input_size = 5 # 入力の次元(特徴量の数)
hidden_size = 50 # LSTMの隠れ層の次元
num_layers = 2 # LSTMの層数
num_classes = 10 # 出力のクラス数
learning_rate = 0.001
num_epochs = 10モデルの準備
model = LSTMModel(input_size, hidden_size, num_layers, num_classes)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)モデル、損失関数、オプティマイザを準備します。
データ例(ダミーデータ)
inputs = torch.randn(8, 10, input_size)
labels = torch.randint(0, num_classes, (8,))ダミーデータとして、8つのサンプル、各サンプルは10のタイムステップを持ち、各タイムステップは5つの特徴量を持つデータを生成します。
inputsはランダムに生成された入力データです。labelsはランダムに生成されたラベルです。
トレーニングループ
model.train()
for epoch in range(num_epochs):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {loss.item():.4f}")
print("トレーニング完了")トレーニングループを実行し、各エポックで損失を計算してモデルを更新します。
…
Epoch 8/10, Loss: 2.2072
Epoch 9/10, Loss: 2.1950
Epoch 10/10, Loss: 2.1821論文:『An estimation method for game complexity(2019)』

- 動的辞書を活用した効率的な特徴抽出
- MoCoは動的辞書とモーメンタム更新を組み合わせ、効率的な特徴抽出を実現します。辞書はキュー構造で管理され、バッチを跨いで多様なネガティブペアを保持。ターゲットエンコーダはモーメンタム更新により一貫性のある特徴を生成し、計算効率を高めつつ判別性の高い表現を学習します。これにより、少ないリソースで転移学習や視覚タスクに適した高品質な特徴を提供します。
- コントラスト学習による判別的な表現学習
- MoCoはコントラスト学習を用い、ポジティブペアとネガティブペアを比較して判別的な特徴を学習します。InfoNCE損失を最適化し、特徴空間で同一クラスを密集させつつ異なるクラスを分離。ポジティブペアは異なる拡張手法で生成され、ネガティブペアは動的辞書から取得。これにより、分類や物体検出など多様なタスクで高品質な特徴抽出を実現します。
- 転移性能の高さと汎用性
- MoCoで学習した特徴は、ImageNetの分類やCOCOでの物体検出・セグメンテーションタスクにおいて高い性能を発揮しました。動的辞書とモーメンタム更新により、多様なネガティブペアを活用して判別的な特徴を抽出。これにより、視覚タスクだけでなく、医療画像処理や異常検知など、さまざまな応用分野でも優れた転移性能を実現しました。MoCoは自己教師あり学習の新たな基盤として、多用途に適用可能なアルゴリズムです。
タスク固有アダプター
Task-Specific Adapters(タスク固有アダプター)は、事前学習済みの大規模モデルに軽量な層を追加し、タスク固有のパラメータだけを学習する転移学習の手法です。この方法により、モデル全体を微調整する必要がなく、効率的に新しいタスクに適応できます。また、リソース消費を抑えながら、事前学習とファインチューニングの間をスムーズに繋げる役割を果たします。そのため、メモリや計算負荷を軽減しつつ、多様なタスクでモデルを活用できる点が特徴です。
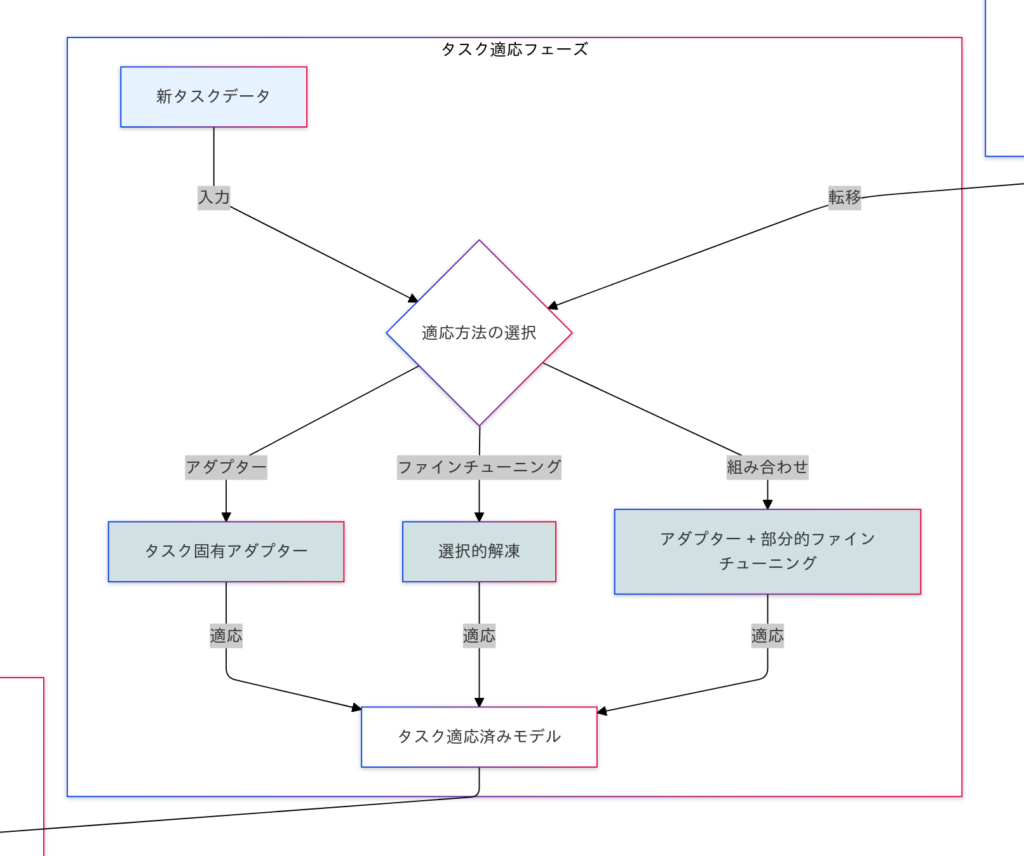
ドメイン適応との違い
- タスク固有アダプターは、事前学習済みモデルに軽量な層を追加し、タスク固有のパラメータのみを学習する手法で、計算コストを抑えつつタスク適応を実現します。一方、ドメイン適応は、ソースドメインとターゲットドメイン間のデータ分布の違いを埋めるための手法です。アダプターはタスク適応が目的で、主にモデル構造の変更に焦点を当てるのに対し、ドメイン適応はデータ分布の調整や学習に重点を置きます。
転移学習における事前学習フェーズとドメイン適応フェーズとタスク固有アダプターフェーズと最終調整フェーズが有機的に繋がるイメージ
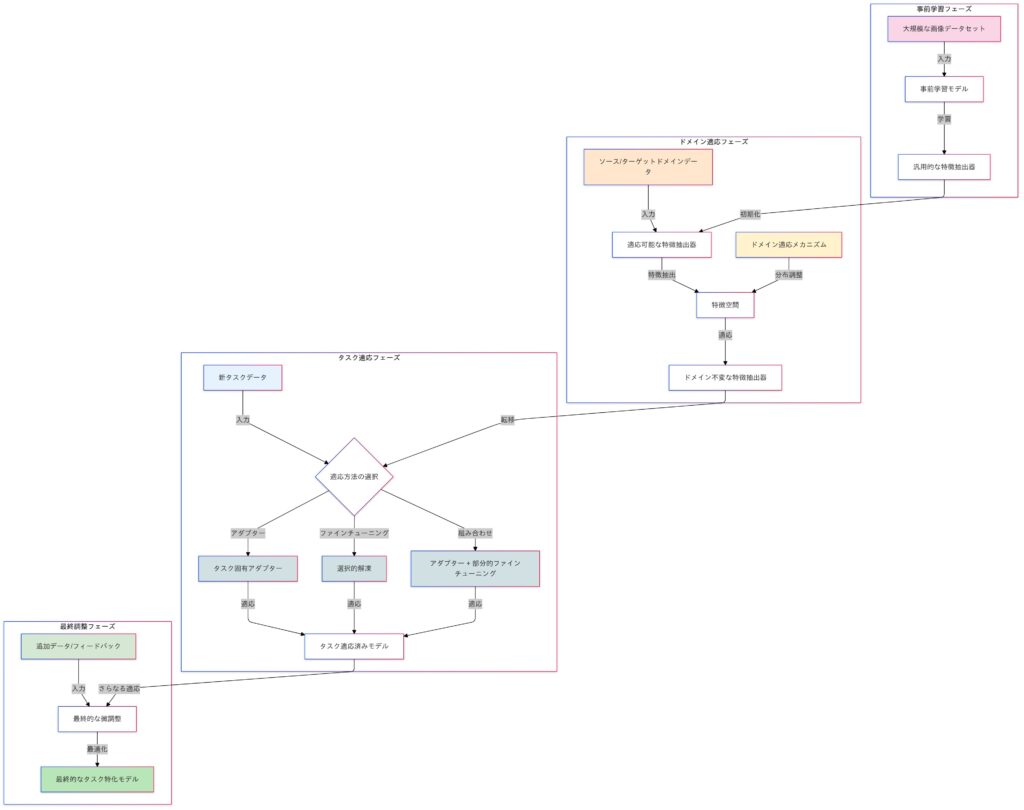
数式:
- Adapter層の出力
$$h’ = f_{\text{adapter}}(h) + h$$
- $h$:事前学習モデルからの中間表現(特徴ベクトル)。
- $f_{\text{adapter}}$:タスク固有のAdapter層(通常、ボトルネック構造を持つ小さなMLP)。
- $h′$:Adapter層を適用後の特徴。
Adapter層は以下のように表現されることが一般的です。
$$f_{\text{adapter}}(h) = W_{\text{down}} \cdot \text{ReLU}(W_{\text{up}} \cdot h)$$
- $W_{\text{down}}$:入力次元をボトルネック次元に縮小するパラメータ。
- $W_{\text{up}}$:ボトルネック次元から元の次元に拡大するパラメータ。
目的:
- 軽量化
- モデル全体を微調整せず、少量の追加パラメータで新しいタスクに適応。
- 効率的な適応
- 複数タスク間で事前学習済みパラメータを共有しつつ、タスク固有の適応を可能にする。
- 汎用性
- 事前学習済みモデルを再利用し、多様なタスクへの適応を迅速に実現
注意点
- 設計の複雑さ
- Adapter層の設計やボトルネック次元の選択がタスクに依存。
- タスク間干渉
- 一部のタスクで学習したAdapterが他のタスクに悪影響を与える可能性。
- 応用範囲の制限
- 特定のタスク(特に極端に異なるドメイン)には効果が限定的。
メリットとデメリット
| メリット | デメリット |
|---|---|
| メモリ効率: 既存のモデルパラメータを固定し、追加のパラメータを最小限に抑える。 | 設計の負担: Adapter層の設計(層の深さやボトルネック次元)に時間がかかる。 |
| 高速学習: 少量のパラメータだけを学習するため、トレーニングが迅速。 | 追加の推論コスト: Adapter層を追加するため、若干の推論時間増加。 |
| タスク間の再利用性: タスク固有のAdapterを切り替えることで、複数タスクへの効率的な適応が可能。 | 性能の限界: モデル全体の微調整(Fine-Tuning)と比較すると、性能が劣る場合がある。 |
| 柔軟性: モデル全体を変更せず、事前学習モデルをそのまま利用可能。 |
適用例
| 適用分野 | 適用例 |
|---|---|
| 自然言語処理(NLP) | BERTやGPTにAdapterを追加し、感情分析や質問応答など特定のタスクに適応。例: Adapter-BERT。 |
| 画像処理 | ImageNetで事前学習したモデルにAdapterを追加し、医療画像解析や物体検出に適用。 |
| 音声処理 | Wav2Vec 2.0などの事前学習済み音声モデルにAdapterを加え、音声分類や音声認識に使用。 |
タスク固有アダプターの実装例:
このコードは、事前学習済みのBERTモデルにAdapter層を追加し、感情分析タスクに適応させるためのものです。Adapter層を使用することで、パラメータ効率を向上させ、事前学習済みモデルの知識を保持しつつ、新しいタスクに適応させることができます。これにより、少量のデータでも高いパフォーマンスを発揮することができます。
事前学習済みモデルのロード
import torch
from transformers import BertModel, BertTokenizer
import torch.nn as nn
# 事前学習済みモデルのロード
bert = BertModel.from_pretrained("bert-base-uncased")BertModelを使用して、事前学習済みのBERTモデルをロードします。bert-base-uncasedは、BERTのベースモデル(小文字のみ)を使用しています。
Adapter層の定義
class Adapter(nn.Module):
def __init__(self, hidden_size, bottleneck_size):
super(Adapter, self).__init__()
self.down = nn.Linear(hidden_size, bottleneck_size)
self.up = nn.Linear(bottleneck_size, hidden_size)
self.relu = nn.ReLU()
def forward(self, x):
return self.up(self.relu(self.down(x))) + xAdapterクラスは、BERTの中間層に追加され、入力の次元を縮小(ダウンサンプリング)してReLU活性化関数を適用後、元の次元に戻す(アップサンプリング)構造を持ち、最終的に元の入力と出力をスキップ接続で加算します。
AdapterをBERTの中間層に組み込む
adapter = Adapter(hidden_size=768, bottleneck_size=64)
for name, param in bert.named_parameters():
param.requires_grad = False # BERT本体のパラメータは固定AdapterインスタンスをBERTの中間層に組み込み、BERT本体のパラメータを凍結して、Adapter層のみを学習対象とします。
最終層を感情分析用に変更
classifier = nn.Linear(768, 2) # 2クラス分類(ポジティブ/ネガティブ)最終層を感情分析用の2クラス分類(ポジティブ/ネガティブ)に対応する全結合層に変更します。
モデルの統合
class AdapterBERT(nn.Module):
def __init__(self, bert, adapter, classifier):
super(AdapterBERT, self).__init__()
self.bert = bert
self.adapter = adapter
self.classifier = classifier
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids, attention_mask=attention_mask)
adapter_output = self.adapter(outputs.last_hidden_state)
logits = self.classifier(adapter_output[:, 0, :]) # [CLS]トークンのみ使用
return logits
model = AdapterBERT(bert, adapter, classifier)
print("Adapter-BERTモデル準備完了")AdapterBERTクラスは、BERTモデル、Adapter層、分類器を統合し、BERTの[CLS]トークンの出力をAdapter層に渡して分類器で処理し、最終的にロジットを取得するモデルを定義します。
タスク固有アダプターは、Adapter層のパラメータのみを更新することで、学習するパラメータ数を削減し、メモリ使用量と計算コストを低減します。また、BERT本体のパラメータを固定して事前学習済みの知識を保持し、少量のデータでも高い性能を発揮します。さらに、各タスクに個別のAdapter層を用いることで、タスク間の干渉を防ぎ、最適なパフォーマンスを実現します。
転移学習における事前学習フェーズとドメイン適応フェーズとタスク固有アダプターフェーズと最終調整フェーズが有機的に繋がるイメージの実装例:
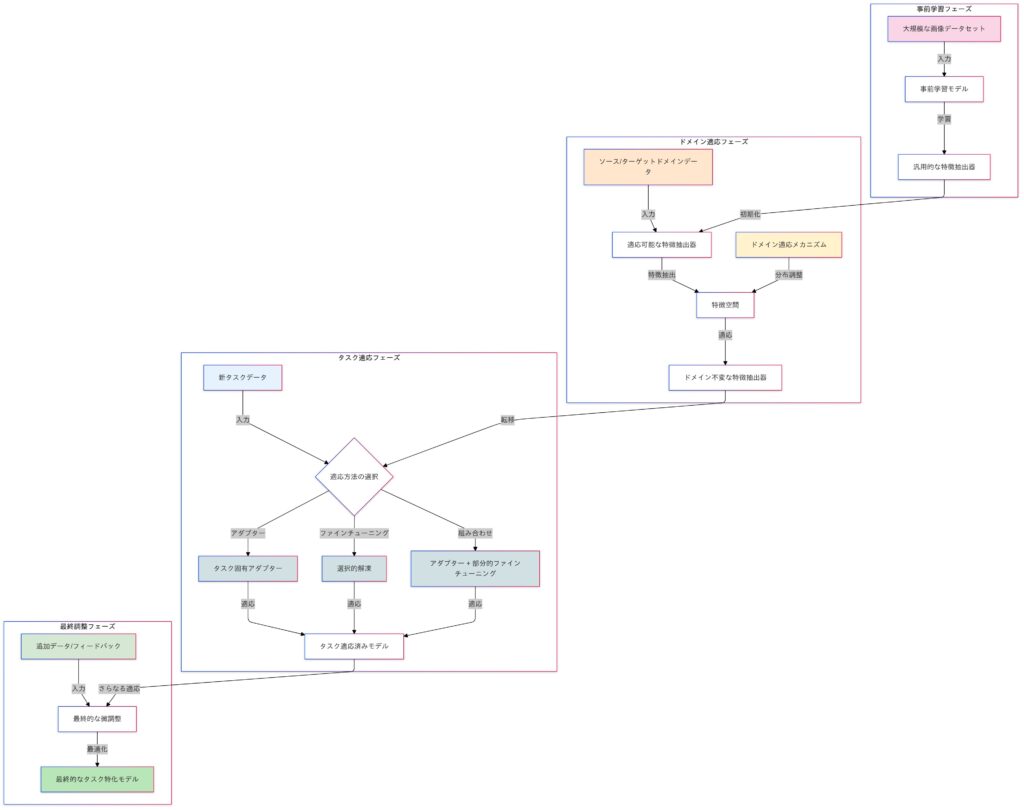
- 事前学習フェーズ
- 事前学習済みのBERTモデル(例: bert-base-uncased)をロードします。
- ドメイン適応フェーズ
- 特定のドメインのデータ(例: ニュース記事)を用意します。
- BERTモデルをこのデータに基づいて調整し、ドメインに適応させます。
- タスク固有アダプターフェーズ
- Adapter層を定義し、BERTの中間層に組み込みます。
- BERT本体のパラメータを固定し、Adapter層のみを学習対象とします。
- 最終層を感情分析用に変更します。
- 最終調整フェーズ
- 感情分析用データセットを用意します。
- トレーニングループを実行し、各エポックで損失を計算してモデルを更新します。
import torch
from transformers import BertModel, BertTokenizer
import torch.nn as nn
import torch.optim as optim
# 事前学習フェーズ
# 事前学習済みモデルのロード
bert = BertModel.from_pretrained("bert-base-uncased")
# ドメイン適応フェーズ
# ドメイン適応用のデータセットを用意(ここではダミーデータ)
domain_data = torch.randint(0, 30522, (32, 128)) # ダミーのトークンID
domain_attention_mask = torch.ones((32, 128)) # ダミーのアテンションマスク
# ドメイン適応用のトレーニング
bert.train()
optimizer = optim.Adam(bert.parameters(), lr=2e-5)
for epoch in range(3): # ドメイン適応のエポック数
optimizer.zero_grad()
outputs = bert(input_ids=domain_data, attention_mask=domain_attention_mask)
loss = outputs.last_hidden_state.mean() # ダミーの損失計算
loss.backward()
optimizer.step()
print(f"Domain Adaptation Epoch {epoch+1}, Loss: {loss.item():.4f}")
# タスク固有アダプターフェーズ
# Adapter層の定義
class Adapter(nn.Module):
def __init__(self, hidden_size, bottleneck_size):
super(Adapter, self).__init__()
self.down = nn.Linear(hidden_size, bottleneck_size)
self.up = nn.Linear(bottleneck_size, hidden_size)
self.relu = nn.ReLU()
def forward(self, x):
return self.up(self.relu(self.down(x))) + x
# AdapterをBERTの中間層に組み込む
adapter = Adapter(hidden_size=768, bottleneck_size=64)
for name, param in bert.named_parameters():
param.requires_grad = False # BERT本体のパラメータは固定
# 最終層を感情分析用に変更
classifier = nn.Linear(768, 2) # 2クラス分類(ポジティブ/ネガティブ)
# モデルの統合
class AdapterBERT(nn.Module):
def __init__(self, bert, adapter, classifier):
super(AdapterBERT, self).__init__()
self.bert = bert
self.adapter = adapter
self.classifier = classifier
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids, attention_mask=attention_mask)
adapter_output = self.adapter(outputs.last_hidden_state)
logits = self.classifier(adapter_output[:, 0, :]) # [CLS]トークンのみ使用
return logits
model = AdapterBERT(bert, adapter, classifier)
# 最終調整フェーズ
# 感情分析用のデータセットを用意(ここではダミーデータ)
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
texts = ["I love this!", "I hate this!"]
inputs = tokenizer(texts, return_tensors="pt", padding=True, truncation=True, max_length=128)
labels = torch.tensor([1, 0]) # ポジティブ: 1, ネガティブ: 0
# トレーニングループ
model.train()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
criterion = nn.CrossEntropyLoss()
for epoch in range(5): # 最終調整のエポック数
optimizer.zero_grad()
outputs = model(input_ids=inputs['input_ids'], attention_mask=inputs['attention_mask'])
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f"Fine-tuning Epoch {epoch+1}, Loss: {loss.item():.4f}")
print("トレーニング完了")Domain Adaptation Epoch 1, Loss: -0.0076
Domain Adaptation Epoch 2, Loss: -0.0136
Domain Adaptation Epoch 3, Loss: -0.0253
tokenizer_config.json: 100%|██████████| 48.0/48.0 [00:00<00:00, 197kB/s]
vocab.txt: 100%|██████████| 232k/232k [00:00<00:00, 763kB/s]
tokenizer.json: 100%|██████████| 466k/466k [00:00<00:00, 1.42MB/s]
Fine-tuning Epoch 1, Loss: 0.5780
Fine-tuning Epoch 2, Loss: 0.6421
Fine-tuning Epoch 3, Loss: 0.6045
Fine-tuning Epoch 4, Loss: 0.6742
Fine-tuning Epoch 5, Loss: 0.6556
トレーニング完了論文1:『Parameter-Efficient Transfer Learning for NLP(2019)』
- Adapter-BERTを提案。BERTのパラメータを固定し、タスク固有のAdapterを学習することで効率的な転移学習を実現。

- 効率的なタスク固有アダプター設計
- アダプターは事前学習モデルの層間に挿入される小型モジュールで、入力特徴量を次元縮小し、非線形変換を経て元の次元に戻します。事前学習済みのパラメータを固定することで、モデル全体の再学習を不要にし、効率的なタスク固有学習を実現。パラメータ数を9分の1以下に削減しつつ、タスク間の干渉を防ぎ、新しいタスクにも柔軟に対応可能です。
- ボトルネック構造によるパラメータ削減
- アダプターは、次元縮小と拡張を行うボトルネック構造を採用し、少ないパラメータでタスク固有の学習を実現します。非線形変換を通じて表現力を確保しながら、必要なパラメータ数をファインチューニングの約9分の1に削減。GLUEタスクで同等の性能を発揮しつつ、計算効率を大幅に向上させます。この設計により、転移学習を効率的かつ柔軟に行える仕組みを提供しています。
- パフォーマンスと効率の両立
- アダプターはGLUEやSQuADなどで、フルファインチューニングに近い性能(GLUE: 平均80.0, SQuAD: F1スコア90.4)を達成。追加パラメータを1.3%に抑え、計算コストを削減しながら高い柔軟性を実現します。新しいタスクにも容易に適用可能で、タスク間の干渉を防ぐ設計が特徴。効率的かつスケーラブルな転移学習を支える仕組みとして、さまざまな応用が期待されています。
論文2:『Adapting BERT for Target-Oriented Multimodal Sentiment Classification(2020)』
- Adapter層を利用して、マルチモーダル感情分析タスクに適用。
https://www.ijcai.org/proceedings/2019/0751.pdf
- ターゲット指向のモダリティ統合
- TomBERTは、ターゲット注意メカニズムを活用し、テキストと画像の関連性を効果的に統合します。ターゲット依存の視覚領域を抽出し、BERTで学習したテキスト特徴と自己注意層を通じて相互作用をモデル化。これにより、複雑なマルチモーダルデータでも、ターゲットごとに適応した特徴表現を生成し、高精度な感情分類を実現します。製品レビューなどのタスクで、視覚情報とテキスト情報を統合的に活用可能な柔軟なアプローチです。
- 柔軟なターゲット表現の生成
- TomBERTは、ターゲット依存の特徴をテキストと画像それぞれで独立に学習し、動的な関連性をモデル化するアダプター的役割を果たします。BERTによる文脈情報の抽出とターゲット注意メカニズムによる視覚領域の強調を組み合わせることで、ターゲット固有の感情分類を実現。複数ターゲットにも柔軟に対応し、高精度なマルチモーダル解析を可能にしています。
- 汎用性と高性能の実証
- TomBERTは、TSCやTMSCタスクで最先端性能を達成し、SemEvalやTwitter-15/17など複数のデータセットで精度向上を実現しました。特に、画像とテキストを統合したモダリティ間相互作用により、ターゲット依存の感情分類が大幅に改善。多様なタスクに適用可能な汎用性を持ち、製品レビューやソーシャルメディア分析など幅広い応用が期待されるモデルです。
論文3:『AdapterFusion: Non-Destructive Task Composition for Transfer Learning(2021)』
- 複数のタスク固有のアダプターを組み合わせて、より強力なモデルを構築するための技術

- タスク固有アダプターのモジュール化設計
- タスク固有アダプターは、事前学習済みモデルの層間に挿入される小型モジュールです。ボトルネック構造を採用し、次元縮小と拡張によりタスク特有の特徴を学習。全体の1~3%の追加パラメータでフルファインチューニングに近い性能を実現し、効率性と柔軟性を両立します。学習済みアダプターは再利用可能で、新たなタスクにも容易に適応できます。
- AdapterFusionによる知識統合
- AdapterFusionは、複数タスクで学習したアダプターの知識を動的に統合する新しい手法です。注意メカニズムを通じて各アダプターの重要度を調整し、タスク間の干渉を回避します。ソフトマックス関数を用いて最適な知識を抽出し、再学習不要で計算コストを削減。実験では、低リソース環境でも高い性能を維持し、自然言語理解タスクで従来手法を上回る結果を示しました。柔軟かつ効率的な転移学習手法として注目されています。
- 再学習不要の拡張性
- AdapterFusionは、タスク固有アダプターを再利用可能な設計で、新しいタスクを追加する際にも既存モデルの再学習が不要です。各タスクのアダプターが独立しているため、破滅的忘却を回避しながら効率的な学習を実現。新しいタスクでは追加のアダプターを学習するだけで対応可能であり、スケーラブルな転移学習を支えます。低リソース環境でも高性能を維持し、多様なタスクへの適用が期待されます。
知識蒸留(Knowledge Distillation)
知識蒸留は、大規模な事前学習モデル(教師モデル)の知識を軽量な生徒モデルに転移する技術であり、その性質から転移学習におけるファインチューニングの派生として機能します。
知識蒸留に関しては前回のブログで紹介しましたので転載しておきます。
転移学習における知識蒸留の目的
知識蒸留は転移学習では、事前学習モデルを新しいタスクに適応する際、すべてのモデルパラメータを更新する(ファインチューニング)か、固定したまま特徴抽出器として利用する(Feature Extraction)アプローチが一般的です。
教師モデルの深い知識をソフトラベルとして生徒モデルに伝えることで、新タスクに効率的に適応しつつ、計算コストを削減します。これにより、一般化性能が向上した軽量な生徒モデルが生成され、転移学習の一環として広く活用できます。
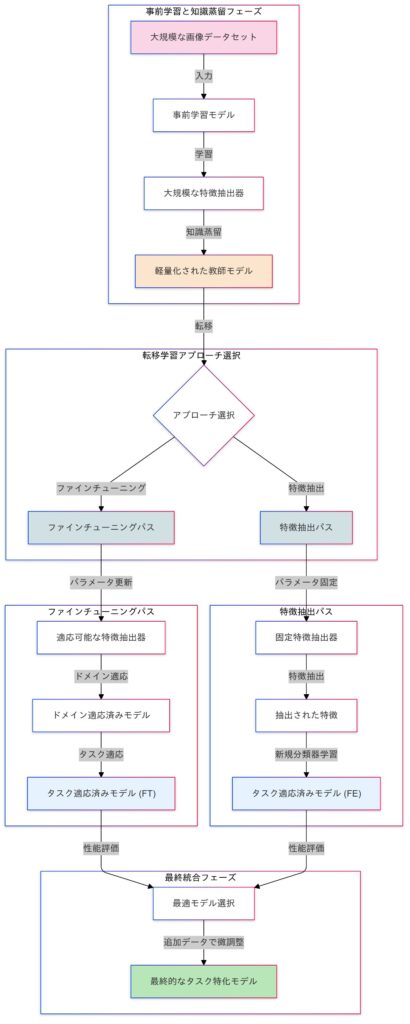
このフローチャートは、知識蒸留を事前学習後の軽量化ステップとして位置づけ、その後のプロセスでファインチューニングと特徴抽出の両方の選択肢を提供しています。これにより、タスクの要件やデータの特性に応じて、最適な転移学習アプローチを選択することが可能になります。
| 利点 | 説明 |
|---|---|
| 柔軟性 | ファインチューニングと特徴抽出の両方のアプローチを利用可能。 |
| 効率的な知識転移 | 知識蒸留を活用して軽量化されたモデルを使用し、効率的な学習と転移を実現。 |
| 適応性 | タスクやデータの特性に応じて最適なアプローチを選択可能。 |
| 性能最適化 | 両アプローチの結果を比較し、最適なモデルを選択することで性能を最大化。 |
モデルの解釈性を向上させる
モデルの解釈性とは?
- ディープラーニングモデルはブラックボックスとみなされがちですが、その決定プロセスを可視化することで、モデルの信頼性や解釈性を向上させることができます。特に、画像分類タスクでは、Grad-CAM(Gradient-weighted Class Activation Mapping)がモデルが注目した領域を視覚的に示す有効な手法として広く利用されています。
Grad-CAMでの可視化
Grad-CAMは、ディープラーニングモデルがどのように決定を下したかを可視化するための技法です。この方法では、勾配情報を利用して、モデルの出力が特定のクラスにどのように関連しているかを可視化します。
つまり特定のクラスに対する決定を導くために、どの部分の画像が重要だったかをヒートマップで表示します。これにより、モデルが誤って決定を下した場合、その原因を追跡することも可能になります。
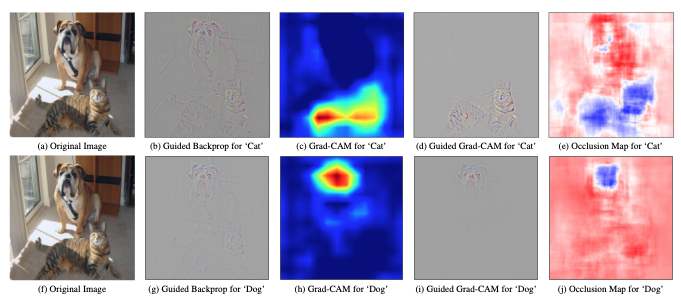
(a) 猫と犬が描かれたオリジナル画像 (b-e) 様々な視覚化による猫カテゴリのサポート。(b) Guided Backpropagation [38]:
(c)Grad-CAM:クラス識別領域を局所化する。(d)(b)と(c)を組み合わせると、Guided Grad-CAMとなり、クラス識別可能な高解像度の可視化が得られる。Grad-CAM技術によって達成されたローカライゼーション(c)は、オクルージョン感度の結果(e)と非常によく似ている。(e)では、青はクラスの証拠に相当する。(c)では、青はクラスに対するスコアが低い領域を示している。図はカラーで見るのが一番良い。
Grad-CAMの仕組み
- ターゲット層の選択
- モデルの中間層(通常は最後の畳み込み層)を選択します。この層は、高次の特徴を捉えており、解釈に最適です。
- 勾配と特徴マップの取得
- フォワードパスで特徴マップを取得し、バックワードパスでターゲットクラスに対する勾配を計算します。
- 勾配の重み付け
- 勾配の平均を取り、特徴マップに対して重み付けを行います。これにより、ターゲットクラスにとって重要な領域が強調されます。
- ヒートマップの生成
- 特徴マップをReLU関数で正の値のみ残し、元の画像サイズにリサイズします。この結果を元画像と重ねることで、Grad-CAMによる可視化が完成します。
数式:
重み$\alpha_{k}^{c}$の定義
Grad-CAMでは、特定のクラス $c$ における特徴マップ $A_k$ の重要度(重み)を次のように定義します。
$$\alpha_{k}^{c} = \frac{1}{Z} \sum_{i} \sum_{j} \frac{\partial Y^{c}}{\partial A_{ij}^{k}}$$
- $Z$ は特徴マップ $A_k$ の空間的サイズ(例:幅 × 高さ)。
- $\frac{\partial Y^{c}}{\partial A_{ij}^{k}}$はクラス $c$ の出力に対する特徴マップの勾配を表します。
- $i, j$ は特徴マップ内の位置インデックス
重みの代替表現
$w_{k}^{c}$を勾配の重み付けの合計として以下のように表します。
$$\omega_{k}^{c} = Z \cdot \alpha_{k}^{c}$$
- この式を$\frac{\partial Y^{c}}{\partial A_{ij}^{k}}$に代入することで次のように整理できます。
$$\alpha_{k}^{c} = \frac{1}{Z} \sum_{i} \sum_{j} \omega_{k}^{c}$$
Grad-CAMマップの定義
Grad-CAMでは、特徴マップ$A_k$を$\alpha_{k}^{c}$で重み付けし、ReLU関数を適用して負の値を除外します。これにより、特定のクラスに関連する正の領域を強調します。
$$L_{\text{Grad-CAM}}^{c} = \text{ReLU} \left( \sum_{k} \alpha_{k}^{c} A^{k} \right)$$
- $A^{k}$は特徴マップ $k$ を表します。
- ReLU 関数を適用することで、負の寄与を取り除きます。
Negative関係の抽出
逆に、負の関係(どこが重要でないか)を抽出する場合、以下の式を用います。
$$L_{\text{Grad-CAM-Neg}}^{c} = \text{ReLU} \left( -\sum_{k} \alpha_{k}^{c} A^{k} \right)$$
この式は、モデルが重要でないと判断した領域を可視化するために用いられます。
解釈
- $L_{\text{Grad-CAM}}^{c}$:モデルが「重要」と判断した領域を強調。
- $L_{\text{Grad-CAM-Neg}}^{c}$:モデルが「重要でない」と判断した領域を強調。
これらを組み合わせることで、モデルの解釈性や信頼性の向上に寄与します。
直感的な理解
- Positive Grad-CAM(どこが重要か):クラス $c$ に強い正の関連を持つピクセルを可視化。
- Negative Grad-CAM(どこが重要でないか):クラス $c$ に負の関連を持つピクセルを可視化。
メリットとデメリット
| メリット | デメリット |
|---|---|
| モデルの決定プロセスを直感的に把握できる。 | 畳み込み層に依存しているため、全結合層では使用できない。 |
| モデルの信頼性向上に寄与。 | 大規模モデルでは計算コストが高くなる。 |
| 医療やセキュリティ分野での応用が可能。 |
適用例
| 適用分野 | 適用例 |
|---|---|
| 医療画像診断 | モデルが腫瘍領域をどのように特定したかを可視化。 |
| 自動運転 | 車両や歩行者を検出する際の注目領域を確認。 |
| 画像分類タスク | モデルが特定のクラスをどのように識別したかを分析。 |
Grad-CAMの実装:
画像分類を使ったGrad-CAMの例
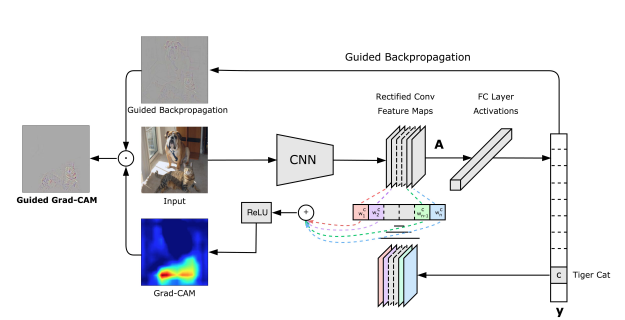
import torch
import torch.nn.functional as F
import torchvision.models as models
import torchvision.transforms as transforms
from PIL import Image
import numpy as np
import cv2
import matplotlib.pyplot as plt
import os
# デバイスの設定(Apple Silicon用)
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
# 事前学習済みモデルのロード(例: ResNet50)
model = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V1)
model.to(device)
model.eval()
# Grad-CAMを生成する関数
def generate_grad_cam(model, input_tensor, target_layer, target_class):
gradients = []
activations = []
# フォワードフックとバックワードフックの定義
def save_gradients(module, grad_in, grad_out):
gradients.append(grad_out[0])
def save_activations(module, input, output):
activations.append(output)
# フックの登録
target_layer.register_forward_hook(save_activations)
target_layer.register_full_backward_hook(save_gradients) # PyTorchの新しいフックに対応
# フォワードパス
output = model(input_tensor)
model.zero_grad()
# ターゲットクラスのスコアを取得してバックワードパス
target = output[:, target_class].sum()
target.backward()
# 重みの計算(勾配の平均)
weights = gradients[0].mean(dim=(2, 3), keepdim=True)
# Grad-CAMマップの計算
# `detach()` を使って計算グラフから切り離し、`.cpu()` でCPUに移動してから `.numpy()` でNumPy配列に変換
grad_cam = F.relu((weights * activations[0]).sum(dim=1)).squeeze().detach().cpu().numpy()
return grad_cam
# 画像の前処理関数
def preprocess_image(image_path):
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# パスの検証
if not os.path.exists(image_path):
raise FileNotFoundError(f"指定されたパスにファイルが存在しません: {image_path}")
if not os.path.isfile(image_path):
raise FileNotFoundError(f"指定されたパスがファイルではありません: {image_path}")
# 画像の読み込み
try:
image = Image.open(image_path).convert("RGB")
except Exception as e:
raise IOError(f"画像の読み込み中にエラーが発生しました: {e}")
# 画像をテンソルに変換
image_tensor = transform(image).unsqueeze(0).to(device)
# オリジナル画像をNumPy配列として取得
original_image = np.array(image)
return image_tensor, original_image
# Grad-CAMの可視化関数
def visualize_grad_cam(image_path, grad_cam):
# 画像の読み込みと検証
try:
image = Image.open(image_path).convert("RGB")
except Exception as e:
raise IOError(f"画像の読み込み中にエラーが発生しました: {e}")
original_image = np.array(image)
# Grad-CAMマップの正規化とリサイズ
grad_cam = cv2.resize(grad_cam, (original_image.shape[1], original_image.shape[0]))
heatmap = cv2.applyColorMap(np.uint8(255 * grad_cam), cv2.COLORMAP_JET)
heatmap = np.float32(heatmap) / 255
overlay = heatmap + np.float32(original_image) / 255
overlay = overlay / np.max(overlay)
return np.uint8(255 * overlay)
# 画像のパス(実際の画像ファイルのパスに置き換えてください)
image_path = '/Users/shion/Desktop/Python/env/ex_dog.png' # 実際のファイル名に変更
# 画像の前処理
try:
input_tensor, original_image = preprocess_image(image_path)
except (FileNotFoundError, IOError) as e:
print(e)
exit(1)
# ターゲットレイヤーとクラスの設定
target_layer = model.layer4[2].conv3 # ResNet50の最後の畳み込み層
output = model(input_tensor)
target_class = output.argmax(dim=1).item() # Predicted class
# Grad-CAMの生成
grad_cam = generate_grad_cam(model, input_tensor, target_layer, target_class)
# Grad-CAMの可視化
try:
overlay_image = visualize_grad_cam(image_path, grad_cam)
except IOError as e:
print(e)
exit(1)
# 結果の表示
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
plt.title("Original Image")
plt.imshow(original_image)
plt.axis("off")
plt.subplot(1, 3, 2)
plt.title("Grad-CAM Heatmap")
plt.imshow(grad_cam, cmap="jet")
plt.axis("off")
plt.subplot(1, 3, 3)
plt.title("Overlay")
plt.imshow(overlay_image)
plt.axis("off")
plt.show()
Grad-CAMを使用することで、モデルの予測に寄与した画像の領域を視覚的に理解することができ、モデルの解釈性を向上させることができます。
論文:『汎用的な視覚的説明手法「Grad-CAM」の提案(2016)』
https://arxiv.org/pdf/1610.02391v1
- 汎用的な視覚的説明手法「Grad-CAM」の提案
- Grad-CAMは、CNNの畳み込み層を活用し、特定のクラスに関連する画像領域をヒートマップで可視化する手法です。モデルのアーキテクチャ変更を必要とせず、予測に寄与した根拠を直感的に理解可能。医療画像解析や物体検出など幅広い分野で活用され、AIシステムの透明性と信頼性向上に貢献します。ただし、低解像度や層選択の影響といった課題もあり、他手法との併用でさらに効果を発揮します。
- Guided Backpropagationとの統合による高解像度化
- Grad-CAMとGuided Backpropagationを組み合わせたGuided Grad-CAMは、クラス識別性と高解像度を兼ね備えた視覚化手法です。Grad-CAMのクラス特化型ヒートマップをGuided Backpropagationの詳細なピクセルレベル視覚化で補完することで、モデルが注目した細かな特徴を効果的に示します。この手法は、医療画像解析や物体検出などでの診断支援や予測エラーの原因分析に活用され、モデルの透明性向上に寄与します。
- モデル解釈の応用と優れた性能
- Grad-CAMは、画像分類や視覚質問応答でモデルの予測根拠を可視化し、透明性と信頼性を向上させます。弱教師付きローカリゼーションタスクでは既存手法を上回る性能を示し、医療画像解析や自動運転など幅広い分野で応用可能です。特に、勾配情報を活用してクラス特化型の重要領域をヒートマップとして視覚化し、誤分類の原因解析やモデルの挙動理解に貢献します。その汎用性と性能により、現代のAIシステムにおける必須のツールとして評価されています。
モデルの保存と再利用を習得する
機械学習やディープラーニングのプロジェクトでは、トレーニング済みモデルを適切に保存し再利用することが、効率的なワークフローを実現する上で非常に重要です。
モデルの保存と再利用が重要な理由
- モデルの保存は、効率的なAIプロジェクトにおいて重要です。トレーニング済みモデルを保存することで、再トレーニングを省略し、推論や新タスクへの適応が迅速に行えます。また、保存したモデルを共有すれば、チーム内での再利用が容易になり、作業の効率化につながります。さらに、モデルを保存することで、トレーニング条件やパフォーマンスを将来にわたり再現でき、プロジェクトの信頼性が向上します。
モデル保存の方法
State Dictによる保存・再利用・転移学習での再利用
- State Dict保存では、モデルのパラメータ(重みとバイアス)のみを保存します。モデルの構造は保存されないため、モデルを再利用する際には、同じモデルのクラス定義を再度記述する必要があります。
モデルの定義
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torchvision import datasets
import torch.nn.functional as F
# デバイスの設定
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
# データの前処理
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# データセットの準備
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=32, shuffle=False)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=32, shuffle=False)
# 拡張CNNモデルの定義
class DilatedCNN(nn.Module):
def __init__(self):
super(DilatedCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, padding=1, dilation=1)
self.bn1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=2, dilation=2)
self.bn2 = nn.BatchNorm2d(64)
self.conv3 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=4, dilation=4)
self.bn3 = nn.BatchNorm2d(128)
self.fc1 = nn.Linear(128 * 4 * 4, 256)
self.dropout = nn.Dropout(0.5)
self.fc2 = nn.Linear(256, 10)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, x):
x = self.pool(F.relu(self.bn1(self.conv1(x))))
x = self.pool(F.relu(self.bn2(self.conv2(x))))
x = self.pool(F.relu(self.bn3(self.conv3(x))))
x = x.view(-1, 128 * 4 * 4)
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x保存(state_dict)
# モデルのインスタンス化
model = DilatedCNN().to(device)
# モデルを保存(state_dict)
torch.save(model.state_dict(), 'DilatedCNN.pth')
print("Model state dict saved.")ロード方法(再利用)
- state_dictで保存をする場合はモデルのクラス定義を再定義する必要があります。
# モデルのクラス定義を再度記述
class DilatedCNN(nn.Module):
def __init__(self):
super(DilatedCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, padding=1, dilation=1)
self.bn1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=2, dilation=2)
self.bn2 = nn.BatchNorm2d(64)
self.conv3 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=4, dilation=4)
self.bn3 = nn.BatchNorm2d(128)
self.fc1 = nn.Linear(128 * 4 * 4, 256)
self.dropout = nn.Dropout(0.5)
self.fc2 = nn.Linear(256, 10)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, x):
x = self.pool(F.relu(self.bn1(self.conv1(x))))
x = self.pool(F.relu(self.bn2(self.conv2(x))))
x = self.pool(F.relu(self.bn3(self.conv3(x))))
x = x.view(-1, 128 * 4 * 4)
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
# 新しいモデルインスタンスを作成
loaded_model = DilatedCNN()
loaded_model.load_state_dict(torch.load('model_state_dict.pth'))
loaded_model.to(device)
loaded_model.eval()転移学習での再利用
- モデルの保存の後で定義したモデルを事前学習済みモデルとしてロードし、新タスクに適応します。
# 事前学習済みモデルのロード
model.load_state_dict(torch.load('DilatedCNN.pth'))
print("Model state dict loaded.")
# 一部の層を固定
for param in model.parameters():
param.requires_grad = False
# 最後の全結合層を新しいタスクに合わせて再定義
model.fc2 = nn.Linear(256, 5) # 例として5クラス分類に変更
model.fc2 = model.fc2.to(device)
# 損失関数とオプティマイザの設定
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.fc2.parameters(), lr=0.001, momentum=0.9)
# トレーニングループ
num_epochs = 10
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(train_loader.dataset)
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {epoch_loss:.4f}")
# 検証ループ
model.eval()
val_running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_running_loss += loss.item() * inputs.size(0)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
val_loss = val_running_loss / len(val_loader.dataset)
val_accuracy = correct / total
print(f"Validation Loss: {val_loss:.4f}, Accuracy: {val_accuracy:.4f}")
print("Training complete")
# モデルの状態辞書を保存
torch.save(model.state_dict(), 'DilatedCNN_transfer.pth')
print("Model state dict saved.")推論での再利用
- 保存されたモデルをロードし、テストデータで推論を実行します。
# テストデータに対する予測
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = loaded_model(inputs)
_, predicted = torch.max(outputs, 1)
print(predicted)モデル全体を保存
全体保存では、モデルの構造とパラメータの両方を一緒に保存します。これにより、モデルの定義を再度行う必要がなく、保存されたファイルをロードするだけでモデルを再利用できます。
保存(全体)
torch.save(model, 'model_full.pth'モデル全体をロード
loaded_model = torch.load('model_full.pth')
loaded_model.to(device)
loaded_model.eval()モデル管理
| ベストプラクティス | 詳細 |
|---|---|
| バージョン管理 | モデルにバージョン番号を付けて管理(例: model_v1.pth, model_v2.pth)。バージョン間の変更点を記録し、比較可能にする。 |
| メタデータの記録 | 保存時に以下の情報を記録:- 使用したデータセットの種類- トレーニング条件(例: エポック数、学習率)- モデルの性能(例: 精度や損失値) |
| クラウドストレージやツールの活用 | クラウドストレージ: AWS S3、Google Driveなどで安全にモデルを保存。モデル管理ツール: Git LFSやDVCを使用して、モデルとデータのバージョン管理を行う。 |
トラブルシューティング
- バージョン互換性の問題
- モデルを保存したPyTorchのバージョンが異なる場合、ロード時にエラーが発生する可能性があります。互換性を確認してください。
- データの不一致
- 再利用時に入力データのフォーマットが異なるとエラーが発生します。保存時と同じデータ前処理を行う必要があります。
モデルのロード方法の違い
- weight_only=Trueを使用したロード方法
model.load_state_dict(torch.load('best_model.pth', weights_only=True))
model.to(device)- PyTorch の最新バージョン(例: PyTorch 2.0 以降)で導入されたオプションで、モデルの重み(
state_dict)のみをロードするため、不要なメタデータや不整合が排除され、訓練時と同じ重みが適用されることで予測性能が安定しやすくなります。
- weights_only=False(デフォルト)を使用したロード方法
model.load_state_dict(torch.load('best_model.pth'))
model.to(device)- PyTorch の従来の動作に従い、保存された全てのオブジェクトやメタデータをロードしますが、モデルのアーキテクチャと一致しない状態や不要な情報が含まれると、予測性能が著しく低下するリスクがあります。
CNNの応用例
この章では様々なCNNの派生モデルを用いてCNNの応用例を探ります。これまで紹介してきた画像分析の他に、時系列データを扱った金融データや音声処理などを紹介しようと思います。
Dilated Causal Convolutions
Causal Dilated Convolutionsは、因果畳み込みと拡張畳み込みを組み合わせた手法で、時系列データにおける因果性の保証と長期依存性の効率的な学習を実現します。特に株価予測や異常検知など、金融時系列データの分析に適した方法です。
Causal Convolution の特徴
- Causal Convolutionは、フィルタが現在および過去のデータのみを参照することで因果性を保証し、未来のデータを見ずに予測を行います。時系列データの順序を保つため、設計が直感的で理解しやすいのが特徴です。ただし、受容野が小さい場合、長期的な依存関係を十分に捉えられない点が課題です。
- 数式:
- 因果畳み込みでは、未来のタイムステップ $t > i$ のデータは使用せず、以下の数式で表現されます
$$y(t) = \sum_{i=0}^{k-1} w(i) \cdot x(t-i)$$
- $x(t−i)$:時刻 $t-i$ の入力データ
- $w(i)$:畳み込みカーネルの重み
- $k$:カーネルサイズ
Dilated Convolution の特徴
Dilated Convolutionは、フィルタの隙間(Dilation Rate)を増やすことで、層を深くせずに受容野を拡大できる効率的な手法です。少ないパラメータで広範囲のデータを捉えられる一方、時間軸の因果性を考慮しないため、時系列データではCausal Convolutionとの併用が一般的です。
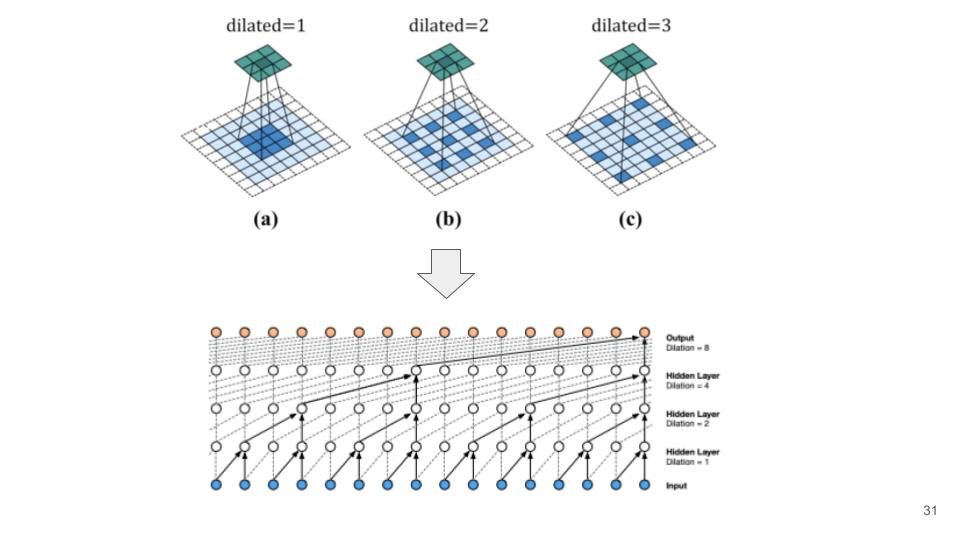
- 数式:
- 拡張畳み込みでは、フィルタの間隔(Dilation Rate ddd)を拡大し、以下の数式で表現されます
$$y(t) = \sum_{i=0}^{k-1} w(i) \cdot x(t – i \cdot d)$$
Dilated Causal Convolutionsの特徴
Causal Dilated Convolutionは、両者の組み合わせで、現在および過去のデータのみを参照することで因果性を保証し、拡張畳み込みにより受容野を効率的に拡大して長期依存性を捉えます。また、計算コストを抑えつつ、金融時系列データのような膨大なデータセットにも対応可能です。
数式:
- 因果性と拡張性を組み合わせると
$$y(t) = \sum_{i=0}^{k-1} w(i) \cdot x(t – i \cdot d), \quad t > i \cdot d$$
この数式により、受容野を拡大しながら未来のデータを使用しない構造を実現します。
目的と課題
| 目的 | 課題 |
|---|---|
| 因果性の維持: 現在および過去のデータのみを使用し、信頼性の高い時系列予測を実現する。 | ハイパーパラメータの調整: Dilation Rateやカーネルサイズの設定がモデル性能に大きく影響する。 |
| 長期依存性の学習: 過去の遠いイベントが現在に与える影響を効果的に学習する。 | データ前処理: ノイズの多い金融データには適切なスケーリングや正規化が必要。 |
メリットとデメリット
| メリット | デメリット |
|---|---|
| 層を深くすることなく広い受容野を実現し、計算コストを削減。 | Dilation Rateを適切に選ばないと、受容野の重複や情報欠落が発生する可能性。 |
| 現在および過去のデータのみを使用し、信頼性の高い時系列予測が可能。 | 大きなDilation Rateを使用すると、細部の特徴を捉えにくくなるリスクがある。 |
| 株価予測や異常検知など、幅広い金融タスクに対応可能。 |
適用例(金融時系列データ)
| 適用例 | 説明 |
|---|---|
| 株価予測 | 過去の価格変動を因果的に学習し、将来の価格を予測。 |
| 異常検知 | 取引量や価格の異常なパターンを検出。 |
| リスク管理 | ポートフォリオのパフォーマンス予測に基づくリスク計算。 |
| アルゴリズム取引 | 短期的な市場動向をキャプチャして取引戦略を最適化。 |
適用例(音声処理)
| 適用例 | 説明 |
|---|---|
| 音声認識 | 時系列の音声波形を因果的に処理し、単語やフレーズを認識。 |
| 感情分析 | 音声波形から感情的な特徴を抽出し、話者の感情状態を判別。 |
| 音声合成 | 入力テキストに基づいて音声を生成し、自然なイントネーションやリズムを再現。 |
| 異常検知 | 機械音や環境音から異常なパターンを検出し、故障や異常イベントを識別。 |
| スピーカー認識 | 音声特徴を基に個々の話者を特定し、認証や識別に活用。 |
Dilated Causal Convolutionsの実装例:
金融時系列データを使ってDilated Causal Convolutionsの実装を行なってみます。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import yfinance as yf
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from torch.utils.data import TensorDataset, DataLoader
# デバイスの設定をMPSに変更(Apple Siliconの場合)
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print(f"Using device: {device}")
# DilatedConvCausal1D クラスの定義
class DilatedConvCausal1D(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, dilation_rate):
super(DilatedConvCausal1D, self).__init__()
self.padding = (kernel_size - 1) * dilation_rate
self.conv = nn.Conv1d(
in_channels,
out_channels,
kernel_size,
dilation=dilation_rate,
padding=self.padding
)
self.activation = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.activation(x)
# 未来の情報を含むパディングを削除
return x[:, :, :-self.padding]
# データの取得(Bitcoinの価格データを使用)
ticker = 'BTC-USD'
data_df = yf.download(ticker, start='2020-01-01', end='2023-12-31')
data = data_df['Close'].values.reshape(-1, 1)
# データの正規化
scaler = MinMaxScaler(feature_range=(0, 1))
data_scaled = scaler.fit_transform(data)
# データの前処理関数
def create_sequences(data, seq_length):
xs, ys = [], []
for i in range(len(data) - seq_length):
x = data[i:i+seq_length]
y = data[i+seq_length]
xs.append(x)
ys.append(y)
return np.array(xs), np.array(ys)
seq_length = 50
X, y = create_sequences(data_scaled, seq_length)
# 訓練データとテストデータの分割(80%訓練、20%テスト)
train_size = int(len(X) * 0.8)
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]
# データをテンソルに変換
X_train = torch.tensor(X_train, dtype=torch.float32).permute(0, 2, 1) # (サンプル数, チャネル数, シーケンス長)
y_train = torch.tensor(y_train, dtype=torch.float32).squeeze() # (サンプル数)
X_test = torch.tensor(X_test, dtype=torch.float32).permute(0, 2, 1) # (サンプル数, チャネル数, シーケンス長)
y_test = torch.tensor(y_test, dtype=torch.float32).squeeze() # (サンプル数)
# データセットとデータローダーの作成
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# モデルのインスタンス化(出力チャネル数を1に変更)
model = DilatedConvCausal1D(in_channels=1, out_channels=1, kernel_size=3, dilation_rate=2)
model.to(device)
# 損失関数とオプティマイザの設定
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# トレーニングループ
num_epochs = 50
best_loss = float('inf')
patience = 5
counter = 0
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for inputs, targets in train_loader:
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
# Conv1Dの出力は [バッチサイズ, 1, シーケンス長_out] なので、最後のタイムステップのみを使用
predictions = outputs[:, :, -1].squeeze() # (バッチサイズ)
loss = criterion(predictions, targets)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(train_loader.dataset)
# バリデーション
model.eval()
val_loss = 0.0
with torch.no_grad():
for inputs, targets in test_loader:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
predictions = outputs[:, :, -1].squeeze()
loss = criterion(predictions, targets)
val_loss += loss.item() * inputs.size(0)
val_loss /= len(test_loader.dataset)
print(f"Epoch {epoch+1}/{num_epochs}, Training Loss: {epoch_loss:.6f}, Validation Loss: {val_loss:.6f}")
# 早期停止のチェック
if val_loss < best_loss:
best_loss = val_loss
counter = 0
torch.save(model.state_dict(), 'best_model.pth')
else:
counter += 1
if counter >= patience:
print("Early stopping triggered.")
break
print("Training complete")
# 最良モデルのロード
try:
model.load_state_dict(torch.load('best_model.pth', weights_only=True))
except TypeError:
# 古いバージョンのPyTorchでは weights_only がサポートされていない場合
model.load_state_dict(torch.load('best_model.pth'))
model.to(device)
# モデルの評価
model.eval()
all_predictions = []
with torch.no_grad():
for inputs, _ in test_loader:
inputs = inputs.to(device)
outputs = model(inputs)
preds = outputs[:, :, -1].squeeze().cpu().numpy() # (バッチサイズ)
all_predictions.extend(preds)
# NumPy配列に変換
all_predictions = np.array(all_predictions)
# スケールを元に戻す
predictions_rescaled = scaler.inverse_transform(all_predictions.reshape(-1, 1)).flatten()
y_test_np = y_test.numpy()
y_test_rescaled = scaler.inverse_transform(y_test_np.reshape(-1, 1)).flatten()
# データシェイプの確認
print(f"y_test_rescaled shape: {y_test_rescaled.shape}") # 期待: (282,)
print(f"predictions_rescaled shape: {predictions_rescaled.shape}") # 期待: (282,)
# 評価指標の計算
mse = mean_squared_error(y_test_rescaled, predictions_rescaled)
mae = mean_absolute_error(y_test_rescaled, predictions_rescaled)
r2 = r2_score(y_test_rescaled, predictions_rescaled)
print(f"MSE: {mse:.4f}, MAE: {mae:.4f}, R2 Score: {r2:.4f}")
# 結果のプロット(テストデータに限定)
plt.figure(figsize=(12, 6))
plt.plot(data_df.index[-len(y_test_rescaled):], y_test_rescaled, label='True Data')
plt.plot(data_df.index[-len(predictions_rescaled):], predictions_rescaled, label='Predictions')
plt.legend()
plt.title('Cryptocurrency Price Prediction')
plt.xlabel('Date')
plt.ylabel('Price')
plt.show()Using device: mps
Training complete
y_test_rescaled shape: (282,)
predictions_rescaled shape: (282,)
MSE: 1356546.8750, MAE: 800.8872, R2 Score: 0.9489
このコードは、Bitcoinの価格データを使用して、ディープラーニングモデルを訓練し、価格予測を行う一連のプロセスを示しています。データの取得から前処理、モデルの定義、訓練、評価、そして結果のプロットまでの全てのステップが含まれています。各ステップで適切なデータ処理とモデルの設定が行われており、最終的な予測結果を視覚的に評価することができます。
論文1:『WaveNet: A Generative Model for Raw Audio(2016)』
- WaveNetによる生オーディオ生成の革新
- WaveNetは、生のオーディオ波形を生成する革新的なディープニューラルネットワークで、従来の音声合成技術を超える自然な音声生成を実現しました。各波形サンプルを逐次予測する確率モデルとして機能し、言語や話者の特徴を条件付けすることで高精度な表現が可能です。また、音声だけでなく音楽や感情音声の生成にも対応し、音声技術の応用範囲を大きく広げました。計算コストの課題はあるものの、その自然さと汎用性は音声合成の新たな基準を打ち立てています。
- 拡張受容野を実現するディレイテッド畳み込み
- ディレイテッド因果畳み込みは、畳み込み間に間隔を設けて受容野を指数的に拡大する技術です。これにより、少ない層で長距離の時間依存性を効率的に学習可能となり、計算コストを抑えつつ音声波形の自然な生成を実現します。また、過去の情報に基づく因果性を保証し、音声の抑揚やリズムといった特徴を正確に再現します。この手法は音声生成だけでなく、音楽生成や時系列予測といった幅広い応用分野でも高い効果を発揮しています。
- 幅広い応用性と優れた性能
- WaveNetは音声認識や音楽生成など幅広いタスクに応用可能で、高い自然性と柔軟性を実現しました。話者IDや言語、感情などを条件として与えることで、マルチスピーカー対応や多様な音声スタイルを生成可能です。また、音楽生成では楽器音やリズムをリアルに再現し、エンターテインメントや教育、医療分野での応用も期待されています。その革新性により、音声処理技術の新たな基準を提示し、さまざまな分野におけるサービスや製品の進化を支えています。
論文2:『An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling(2018)』

- 時系列モデリングにおける新しいアプローチ「TCN」の提案
- TCNは、因果性を保証するディレイテッド畳み込みと残差接続を組み合わせた新しい時系列モデリング手法です。受容野を指数的に拡大し、長期依存性を効率的に捉える一方、並列計算により学習時間を短縮します。残差接続が学習の安定性を向上させ、勾配消失問題も軽減。自然言語処理や音声認識など幅広いタスクでRNNを上回る性能を発揮し、時系列解析の新たな基準を提示しました。
- RNNとの比較で示された優越性
- TCNは、LSTMやGRUと比較して、時系列タスク全般で高い性能を発揮します。ディレイテッド畳み込みが長期依存性を効果的に捉え、残差接続が学習の安定性を向上。並列計算により高速な学習が可能で、タスクごとの調整が最小限で済む汎用性も特徴です。シーケンシャルMNISTなどの長期記憶タスクやシーケンス分類で安定した結果を達成し、時系列解析の効率的な新基準を提示しています。
- 幅広い応用と設計の柔軟性
- TCNは、MNIST系列、音楽生成、言語モデリングなど幅広いタスクで高精度を達成しました。ディレイテッド畳み込みにより短期から長期依存性まで柔軟に対応し、並列計算で学習速度を向上。多様な時系列データへの適応力が高く、自然言語処理や金融データ解析などの分野で実用性を発揮しています。設計がシンプルで拡張性も高く、時系列モデリングにおける新たな基準を確立しました。
Hybrid CNN-RNN Models
Hybrid CNN-RNNモデルは、畳み込みニューラルネットワーク(CNN)とリカレントニューラルネットワーク(RNN)を統合したモデルで、短期的な特徴を抽出するCNNと、長期的な時系列依存関係を捉えるRNNの特性を組み合わせています。このアーキテクチャは、金融時系列データのように局所的なパターンと長期的な依存関係が重要な分野で特に有用です。
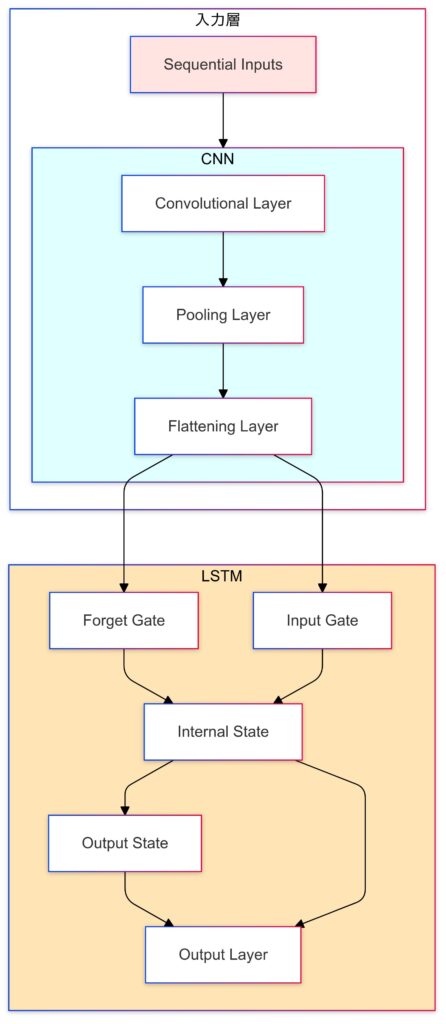
特徴:
- 短期パターンの抽出(CNN)
- CNNは、時系列データの短期間で顕著な変化を効率的にキャプチャします。
- 金融データの局所的なトレンドや異常を検出するのに適しています。
- 長期依存性の学習(RNN)
- RNN(LSTMやGRU)は、抽出された特徴を連続的に処理し、長期的な依存関係や全体的なトレンドを学習します。
- 組み合わせのメリット
- CNNの高速な計算とRNNの時系列モデリング能力を統合することで、高度な予測精度を実現します。
数式:
- CNNによる特徴抽出
$$F=CNN(X)$$
$X$:時系列データ(例: 株価、取引量)。$F$:CNNによって抽出された特徴。
- RNNによる時系列モデリング
$$H_t=RNN(F_t,H_{t−1})$$
$F_t$:CNNが出力する特徴の時刻 $t$ の値。$H_t$:時刻 $t$ におけるRNNの隠れ状態。
- 最終出力
$$y=Dense(H_T)$$
$H_T$:最終時刻 $T$ の隠れ状態。$y$:予測値(例: 次期の株価)。
目的と課題
| 目的 | 課題 |
|---|---|
| 局所的および全体的なパターンの学習: 金融データの短期的な変動を抽出し、長期的なトレンドや依存関係を学習。 | モデルの複雑さ: CNNとRNNの統合により、計算コストが高くなる。 |
| 複雑な相関の理解: 多変量データ間の非線形な相関をモデル化。 | 過学習のリスク: パラメータが多いため、学習データに依存しすぎる可能性。 |
| 予測精度の向上: CNNとRNNの統合により、精度と汎化能力を両立。 | データ準備の難しさ: 時系列データを効果的にCNNに入力する前処理が必要。 |
メリットとデメリット
| 観点 | メリット | デメリット |
|---|---|---|
| 性能 | 局所的なパターンと長期依存性を同時に学習可能。 | 複雑な構造により、計算コストが高い。 |
| 汎用性 | 時系列データだけでなく、多変量や非時系列データにも適用可能。 | モデルの設計とハイパーパラメータの調整が難しい。 |
| 精度 | 単独のCNNやRNNよりも高い精度を実現。 | 過学習のリスクが高い。 |
適用例:金融
- 株価予測
- 局所的な変動パターンと全体的な市場トレンドを同時に予測。
- リスク管理
- 異常検知や信用スコアリングに応用。
- 取引戦略
- 高頻度取引でのパターン分析。
Hybrid CNN-RNN Modelsの実装例:
金融時系列データを使ってHybrid CNN-RNN Modelsの実装を行ないます。以下のフローチャートに沿った流れでコードを実装していきます。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import yfinance as yf
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from torch.utils.data import TensorDataset, DataLoader
# デバイスの設定をMPSに変更(Apple Siliconの場合)
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print(f"Using device: {device}")
# CNN部分(短期パターン抽出)
class CNNModule(nn.Module):
def __init__(self, input_channels, output_channels, kernel_size):
super(CNNModule, self).__init__()
self.conv1 = nn.Conv1d(input_channels, output_channels, kernel_size, padding=(kernel_size - 1))
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=0.5)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.dropout(x)
return x
# RNN部分(長期依存性の学習)
class RNNModule(nn.Module):
def __init__(self, input_size, hidden_size, num_layers):
super(RNNModule, self).__init__()
self.rnn = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True, dropout=0.5)
def forward(self, x):
output, _ = self.rnn(x)
return output
# ハイブリッドモデル
class HybridCNNRNN(nn.Module):
def __init__(self, cnn_output_channels, rnn_hidden_size, num_classes):
super(HybridCNNRNN, self).__init__()
self.cnn = CNNModule(input_channels=1, output_channels=cnn_output_channels, kernel_size=3)
self.rnn = RNNModule(input_size=cnn_output_channels, hidden_size=rnn_hidden_size, num_layers=2)
self.fc = nn.Linear(rnn_hidden_size, num_classes)
def forward(self, x):
x = self.cnn(x)
x = x.permute(0, 2, 1) # (batch, seq_len, features) for RNN
x = self.rnn(x)
x = x[:, -1, :] # 最後の時刻の出力を取得
x = self.fc(x)
return x
# データの取得(Bitcoinの価格データを使用)
ticker = 'BTC-USD'
data_df = yf.download(ticker, start='2020-01-01', end='2023-12-31')
data = data_df['Close'].values.reshape(-1, 1)
# データの正規化
scaler = MinMaxScaler(feature_range=(0, 1))
data_scaled = scaler.fit_transform(data)
# データの前処理関数
def create_sequences(data, seq_length):
xs, ys = [], []
for i in range(len(data) - seq_length):
x = data[i:i+seq_length]
y = data[i+seq_length]
xs.append(x)
ys.append(y)
return np.array(xs), np.array(ys)
seq_length = 50
X, y = create_sequences(data_scaled, seq_length)
# 訓練データとテストデータの分割(80%訓練、20%テスト)
train_size = int(len(X) * 0.8)
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]
# データをテンソルに変換
X_train = torch.tensor(X_train, dtype=torch.float32).permute(0, 2, 1) # (サンプル数, チャネル数, シーケンス長)
y_train = torch.tensor(y_train, dtype=torch.float32).squeeze() # (サンプル数)
X_test = torch.tensor(X_test, dtype=torch.float32).permute(0, 2, 1) # (サンプル数, チャネル数, シーケンス長)
y_test = torch.tensor(y_test, dtype=torch.float32).squeeze() # (サンプル数)
# データセットとデータローダーの作成
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# モデルのインスタンス化(出力チャネル数を1に変更)
model = HybridCNNRNN(cnn_output_channels=64, rnn_hidden_size=128, num_classes=1)
model.to(device)
print(model)
# 損失関数とオプティマイザの設定
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 学習率スケジューラの追加
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=2, verbose=True)
# トレーニングループ
num_epochs = 100 # エポック数を増やす
best_loss = float('inf')
patience = 10 # 早期停止の忍耐回数を増やす
counter = 0
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for inputs, targets in train_loader:
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs.squeeze(), targets)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(train_loader.dataset)
# バリデーション
model.eval()
val_loss = 0.0
with torch.no_grad():
for inputs, targets in test_loader:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs.squeeze(), targets)
val_loss += loss.item() * inputs.size(0)
val_loss /= len(test_loader.dataset)
# 学習率スケジューラのステップ
scheduler.step(val_loss)
print(f"Epoch {epoch+1}/{num_epochs}, Training Loss: {epoch_loss:.6f}, Validation Loss: {val_loss:.6f}")
# 早期停止のチェック
if val_loss < best_loss:
best_loss = val_loss
counter = 0
torch.save(model.state_dict(), 'best_model.pth')
else:
counter += 1
if counter >= patience:
print("Early stopping triggered.")
break
print("Training complete")
# 最良モデルのロード
try:
model.load_state_dict(torch.load('best_model.pth', map_location=device))
except TypeError:
# 古いバージョンのPyTorchでは map_location が必要かもしれません
model.load_state_dict(torch.load('best_model.pth', map_location=device))
model.to(device)
# モデルの評価
model.eval()
all_predictions = []
with torch.no_grad():
for inputs, _ in test_loader:
inputs = inputs.to(device)
outputs = model(inputs)
preds = outputs.squeeze().cpu().numpy() # (バッチサイズ)
all_predictions.extend(preds)
# NumPy配列に変換
all_predictions = np.array(all_predictions)
# スケールを元に戻す
predictions_rescaled = scaler.inverse_transform(all_predictions.reshape(-1, 1)).flatten()
y_test_np = y_test.numpy()
y_test_rescaled = scaler.inverse_transform(y_test_np.reshape(-1, 1)).flatten()
# データシェイプの確認
print(f"y_test_rescaled shape: {y_test_rescaled.shape}") # 期待: (282,)
print(f"predictions_rescaled shape: {predictions_rescaled.shape}") # 期待: (282,)
# 評価指標の計算
mse = mean_squared_error(y_test_rescaled, predictions_rescaled)
mae = mean_absolute_error(y_test_rescaled, predictions_rescaled)
r2 = r2_score(y_test_rescaled, predictions_rescaled)
print(f"MSE: {mse:.4f}, MAE: {mae:.4f}, R2 Score: {r2:.4f}")
# テストデータの開始インデックス
test_start_index = train_size + seq_length
# テストデータに対応する日付を取得
test_dates = data_df.index[test_start_index:test_start_index + len(y_test_rescaled)]
# 結果のプロット(テストデータに限定)
plt.figure(figsize=(12, 6))
plt.plot(test_dates, y_test_rescaled, label='True Data')
plt.plot(test_dates, predictions_rescaled, label='Predictions')
plt.legend()
plt.title('Cryptocurrency Price Prediction')
plt.xlabel('Date')
plt.ylabel('Price')
plt.show()Using device: mps
Training complete
y_test_rescaled shape: (282,)
predictions_rescaled shape: (282,)
MSE: 1716926.0000, MAE: 1010.0507, R2 Score: 0.9353
モデルの評価が低いため、まだ改善の余地がありそうです。
改善のための提案
- データの品質向上:
- データの前処理を再確認し、ノイズや異常値を適切に処理する。
- より多くの特徴量や異なるテクニカル指標を追加する。
- モデルの再設計:
- ハイパーパラメータ(学習率、バッチサイズ、エポック数など)の調整。
- モデルアーキテクチャの見直し。例えば、層の数やユニット数の変更。
- 学習方法の改善:
- 過学習を防ぐために正則化手法を導入。
- 早期停止の基準を再評価。
- 評価指標の見直し:
- 他の評価指標(例えば、平均絶対パーセント誤差(MAPE))も併用してモデル性能を評価する。
- データ拡張:
- 時系列データの拡張手法を検討し、モデルの一般化能力を向上させる。
これらの修正を適用することで、モデルの予測性能の改善が期待できそうです。
論文:『Modeling Long- and Short-Term Temporal Patterns with Deep Neural Networks(2017)』

- 長短期依存関係を統合したLSTNetの提案
- LSTNetは、短期依存を畳み込み層で、長期依存をリカレント層で、周期的パターンをリカレントスキップ接続でモデル化します。また、自己回帰(AR)を統合し、スケール変動にも対応可能。これにより、時系列データの複雑な依存関係を包括的に捉え、高精度かつ汎用的な予測を実現しました。交通量や電力消費など多様なデータに適応し、並列計算を活用した効率的な学習が可能な設計が特徴です。
- 時系列データの周期性を活用
- LSTNetは、リカレントスキップ接続を導入し、時系列データの周期的パターンを効率的に学習します。この接続により、長期的な周期性を直接捉え、従来のリカレントモデルでは難しかった長周期の依存性もモデル化可能に。例えば、24時間の周期を持つデータでは、その間隔で過去の情報をスキップ接続し、データの周期性を効果的に活用。これにより、特に長期予測において高い精度と効率的な学習を実現しました。
- 実世界データでの高性能を実証
- LSTNetは、電力消費や交通量予測など実世界の時系列データで高い予測性能を実証しました。短期、長期、周期的依存関係を統合的にモデリングし、既存手法を上回る精度を達成。特に周期性が明確なデータ(例: ソーラーエネルギー生成)では大幅な性能向上を示しました。また、多変量データへの適応性や計算効率の高さから、金融市場予測や医療データ解析など多様な分野への応用可能性が期待されています。
学習の振り返りと次回予告
今回の学習では、畳み込みニューラルネットワーク(CNN)の基本構造を理解し、転移学習を活用した実践的なモデル構築を行いました。CNNの畳み込み層やプーリング層の役割を数式や図で深く学ぶとともに、拡張CNNを用いて性能向上を図りました。特に、転移学習では事前学習済みモデルを活用し、少ないデータで高精度なモデルを構築する方法を体験しました。また、Grad-CAMやヒートマップでモデルの解釈性と信頼性を向上させる技術を学び、応用力を高めることができました。
次回は時系列データ、自然言語処理、音声学習の実装をテーマに学習を進めていきます。特に、時系列データを扱うRNN、LSTM、GRUの仕組みと実装に取り組みます。
また、時系列データを効果的に処理するためのモデル設計や、それを活用した具体的な応用例についても詳しく解説します。次回も理論と実践を通じて、新たなスキルを習得し、応用力を高めていきましょう!


コメント