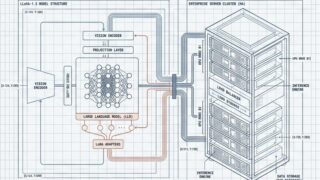
 VLM
VLM 【VLM】LLaVA-1.5 論文解説&VLM完全ガイド|基礎から本番運用まで
はじめにVision Language Model(VLM)の歴史において、一つの分岐点とも言える論文が存在します。2023年版の 「Improved Baselines with Visual Instruction Tuning (LL...
VLM  画像生成
画像生成  基礎理論
基礎理論  基礎理論
基礎理論 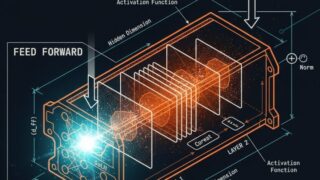 基礎理論
基礎理論  基礎理論
基礎理論  基礎理論
基礎理論  LLM
LLM  Claude
Claude  論文
論文