
前提知識
機械学習を使った機械学習ファイナンスを学ぶ前提知識として、学んでおいた方が良いこととその学び方について説明をしていますので、機械学習ファイナンス初心者の方は是非目を通してみてください。

はじめに
機械学習ファイナンスとは、Pythonなどのプログラミング言語を用いて、あらかじめ決められた取引ルールに基づいて自動で株式や通貨の売買を行う手法です。特に、膨大なデータを処理し、取引の判断を短時間で行える点が特徴で、証券会社に勤務する証券マンや、ヘッジファンド、プロのトレーダーがその効率性を活用しています。近年では、機械学習技術を組み合わせて、市場データのパターンを学習し、将来の価格変動を予測する機械学習ファイナンスがますます重要視されています。
このブログシリーズでは、Pythonを使って機械学習を活用した機械学習ファイナンスの基礎から実践までを段階的に学びます。最終的には、機械学習アルゴリズムを実装し、自動で取引戦略を構築・最適化できるスキルを身につけることを目指します。
今回の第一回では、まずPythonの環境設定や基本操作について学びます。Pythonは機械学習ファイナンスにおいて強力なツールであり、特に機械学習を行う際には欠かせません。また、数値データを効率的に操作するためのNumPy、データフレームを扱うためのPandasといった主要ライブラリの使い方も実践していきます。さらに、次回以降に活用するための機械学習ライブラリであるscikit-learn、PyTorch、TensorFlow、Kerasのインストール方法も紹介します。
これから手を動かしながらPythonと機械学習の基礎をしっかり習得し、機械学習ファイナンスに応用できる知識を身につけていきましょう!
PythonとJupyterLabの環境設定
機械学習ファイナンスを始めるためには、まずPythonの環境を整えることが必要です。ここでは、初心者の方でも簡単にセットアップできるように、Anacondaを使ったPythonのインストール方法と、Jupyter Labという便利な開発環境のセットアップ方法を解説します。Anacondaは、Pythonのパッケージ管理や環境構築を簡単にしてくれるオープンソースのディストリビューションです。
Anacondaのインストール方法
Anacondaのインストールは非常に簡単です。以下の手順に従って進めてください。
Anacondaの公式サイトにアクセスし、使用しているOS(Windows、MacOS、Linux)に合ったインストーラをダウンロードします。
登録をスキップをクリックするとAnacondaインストーラーの画面が表示されますのでご自分のPC環境に合わせてAnacondaをインストールしてください。
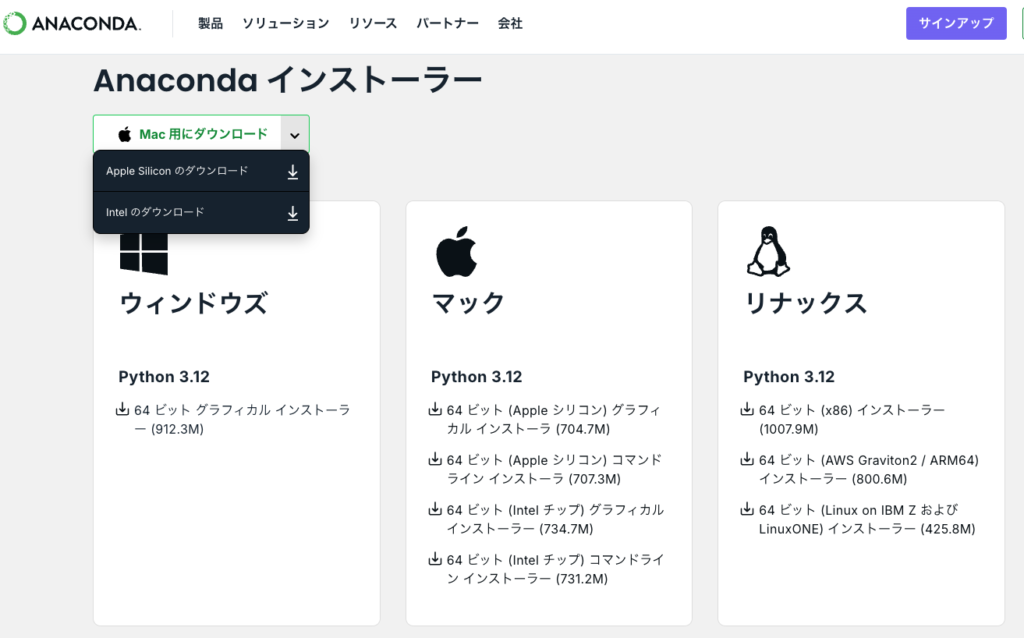
ダウンロードが完了したら、インストーラを起動し、画面の指示に従ってインストールを進めます。インストールの途中で、「PATHに追加する」オプションが表示された場合は、それを有効にしてください。
インストールが完了したら、ターミナル(Windowsの場合はAnaconda Prompt、MacやLinuxの場合はターミナル)を開き、以下のコマンドを入力して、正しくインストールされたか確認します。

正しくインストールされていれば、conda 23.x.x のようにバージョンが表示されます。
JupyterLabのセットアップ
次に、Jupyter Labを使ってPythonコードを書ける環境をセットアップします。Jupyter Labはブラウザ上でPythonのコードをインタラクティブに実行できるツールで、データの可視化やアルゴリズムのテストに最適です。
JupyterLabは、Jupyter Notebookの進化版で、より使いやすいインターフェースと拡張性を持っています。データ分析や機械学習の開発に最適な環境です。
Anacondaをインストールした状態では、JupyterLabを簡単にインストールできます。まず、Anaconda Promptまたはターミナルを開き、以下のコマンドを入力してJupyterLabをインストールします。
conda install -c conda-forge jupyterlab途中で「Proceed(y/n)?」と表示されますが「y」と入力してEnter。
インストールが完了したら、以下のコマンドでJupyterLabを起動します。
jupyter labブラウザが自動的に開き、JupyterLabのインターフェースが表示されます。ここから新しいノートブックを作成し、Pythonコードを書いて実行できます。
CursorやVSCodeを使った環境設定
最近は、Cursor や VSCode などのエディタを使って、より高度な開発環境を構築することも非常に人気があります。特に、CursorやVSCodeでは、ChatGPTのようなAIを使って、コードの作成やデバッグを手助けする機能があるため、効率的に開発を進められます。
Cursorを使った環境設定
Cursor は、特にAIアシスタントと連携して、リアルタイムでコード作成や説明を受けることができる新しいエディタです。
まず、Cursorの公式サイトからインストーラをダウンロードしてインストールします。公式サイトでは、使用しているOSに合わせたバージョンを選択できます。
Cursorの公式サイト
インストール後、Cursorを起動すると、画面右側にAIチャット機能が表示されます。ここで、Pythonコードに関する質問を投げかけたり、特定のコードを生成してもらうことができます。
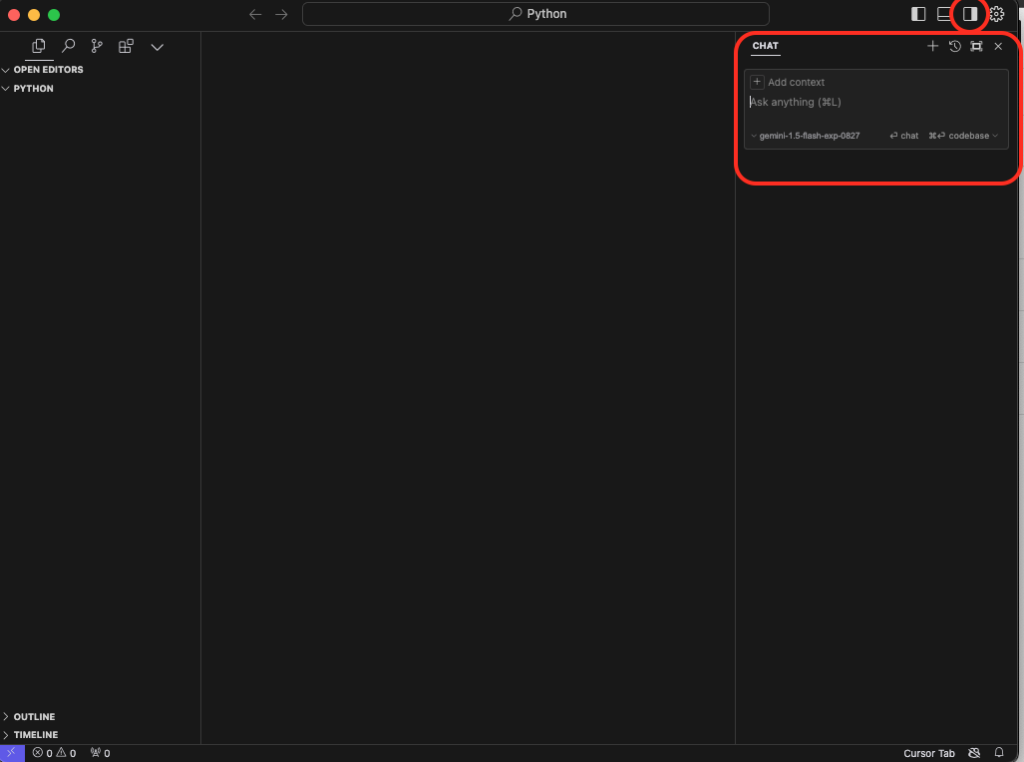
インストールが完了したら、Pythonの拡張機能をインストールします。拡張機能アイコンをクリックし、「Python」を検索してインストールします。
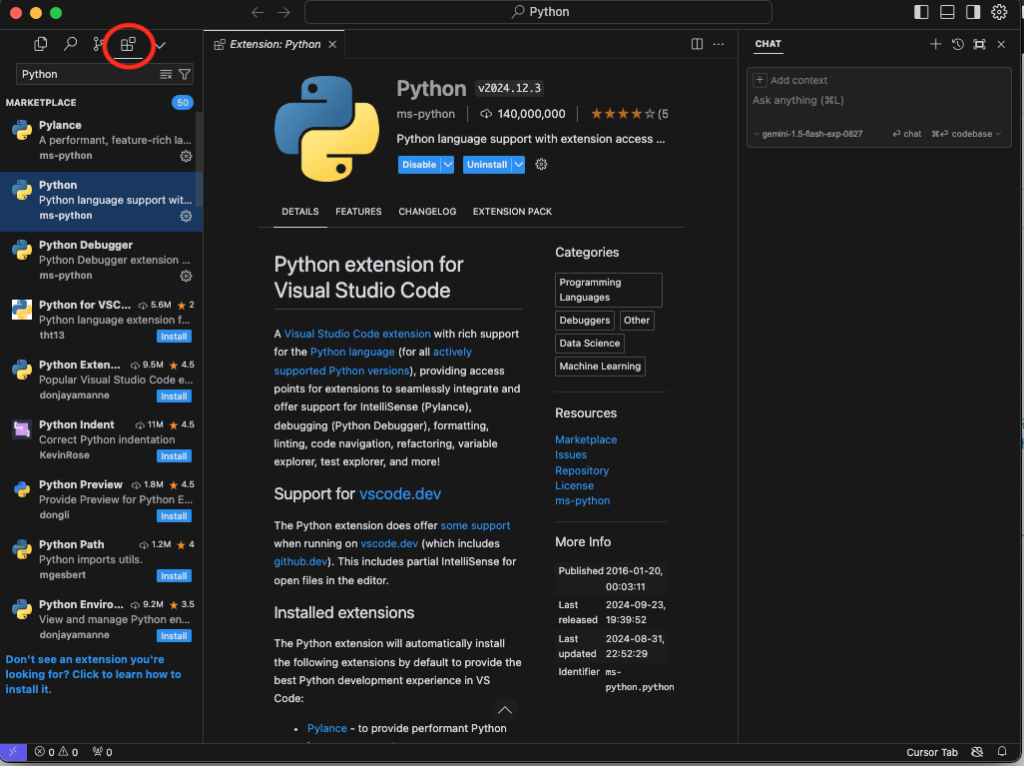
次にJupyterの拡張機能をインストールします。拡張機能アイコンをクリックし、「Jupyter」を検索してインストールします。
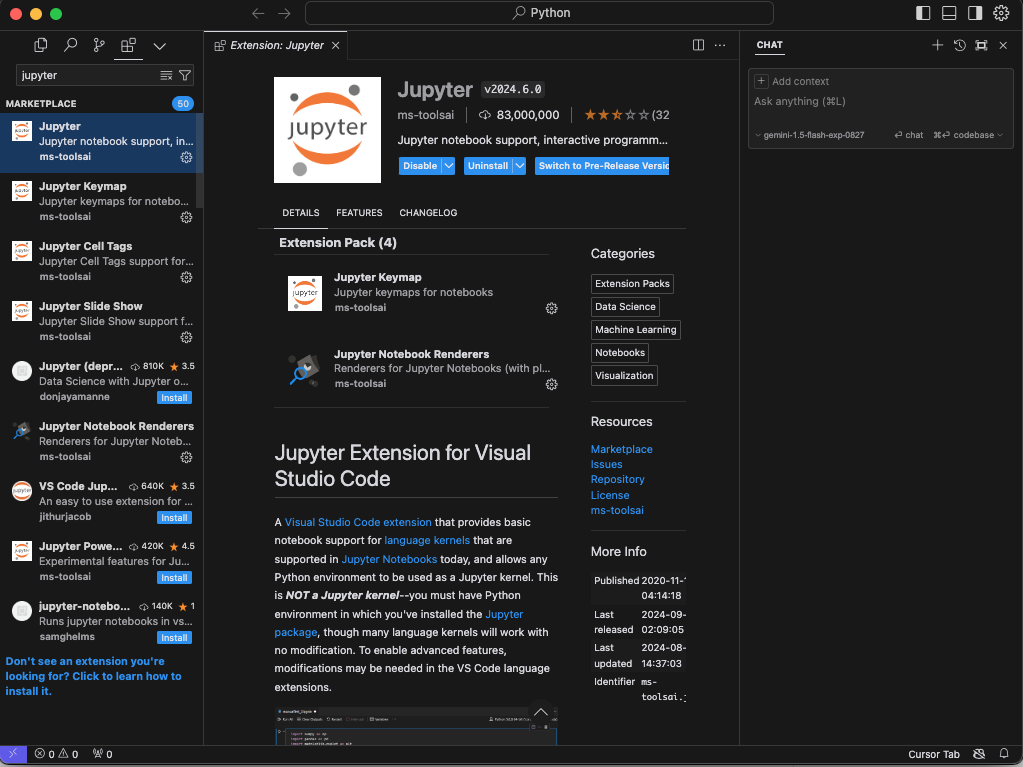
初期設定が完了したら、プロジェクトを作成し、Pythonコードを記述していきます。例えば、「Pythonで簡単な関数を作成して」という指示をチャットで送信すると、AIがコードを生成してくれるため、トレード戦略の構築も迅速に進めることができます。
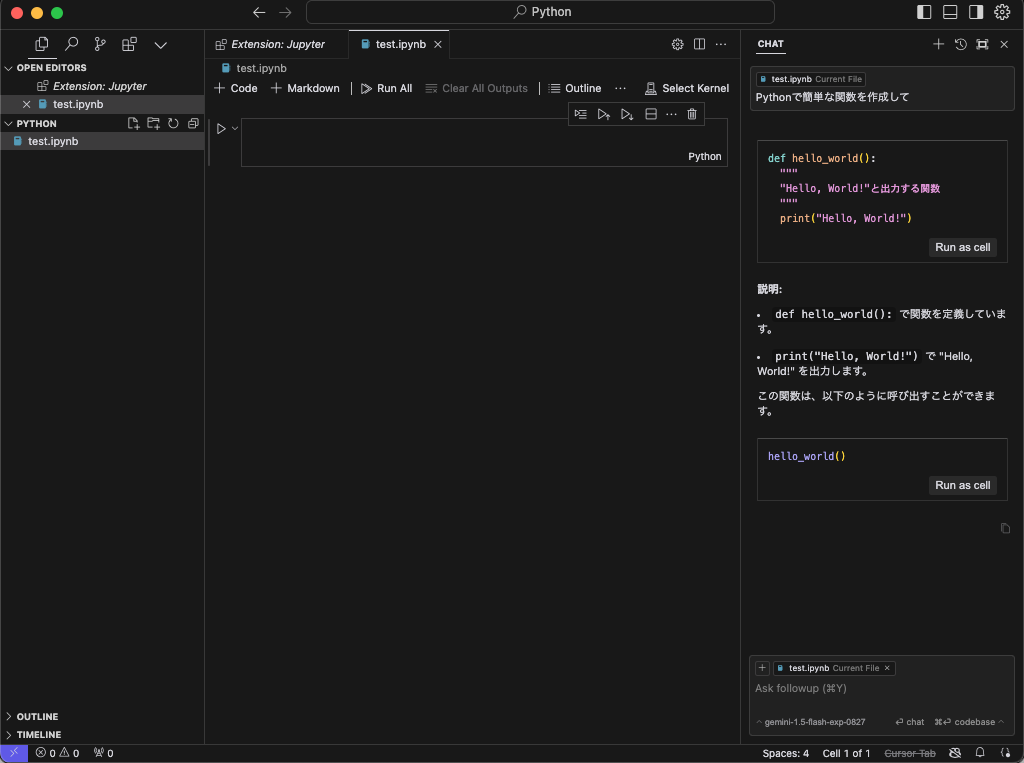
Cursorのチャット機能を使えば、コードの説明やデバッグもAIに依頼できるため、複雑なアルゴリズムの開発を効率的に行えます。
VSCodeを使った環境設定
Visual Studio Code (VSCode) は、Microsoftが開発した無料のエディタで、多くの拡張機能を利用して高度な開発が可能です。特に、Pythonや機械学習のプロジェクトに最適なツールとして広く使われています。
まず、VSCodeの公式サイトからエディタをダウンロードし、インストールします。
インストールが完了したら、Corsorの時と同様にPythonの拡張機能をインストールします。VSCodeを開き、左側の拡張機能アイコンをクリックし、「Python」を検索してインストールします。同様に「Jupyter」の拡張機能もインストールします。
VSCodeでは、インテリセンス(コード補完)機能やデバッガーが非常に強力で、エラーを見つけたり、コードを最適化するのに役立ちます。また、Git との連携や、データ分析に必要なツールも豊富に揃っているため、プロジェクト全体を管理するのにも最適です。
最近では、VSCodeにもAIによるコードアシスタント機能(Copilotなど)が導入されており、コードの自動生成やデバッグの支援を受けられます。例えば、機械学習ファイナンスに必要な戦略を提案してもらったり、複雑な計算ロジックを自動で補完してもらうことができます。
環境設定のまとめ
- JupyterLabは、データ分析やアルゴリズムの実験に最適で、インタラクティブな環境を提供します。
- Cursorを使えば、AIのサポートを受けながらリアルタイムでコードを書けるため、効率的に開発を進めることが可能です。
- VSCodeは、拡張性の高いエディタで、大規模なプロジェクトや多様なプラグインを使った開発に向いています。
お疲れ様でした。各ツールにはそれぞれの強みがあるので、自分の好みに合った環境を選んでください。
Pythonの基本操作
Pythonの基礎を理解することは、機械学習ファイナンスを実装するための重要なステップです。このセクションでは、Pythonの基本的な文法や構造を学び、変数、データ型、リスト、辞書、関数などの基本要素を理解していきます。まずは、簡単なコード例を見て、自分で実際に手を動かして試してみましょう。わかりやすそうなPythonの教則本を一冊読んでおくとスムーズに理解できると思います。
変数とデータ型
Pythonでは、データを保存するために「変数」を使用します。変数には数値、文字列、リストなどさまざまなデータ型を割り当てることができます。
変数とデータ型の基本例
# 整数型の変数
x = 10
# 浮動小数点型の変数
y = 3.14
# 文字列型の変数
message = "Hello, Python!"上記の例では、x は整数、y は小数、message は文字列がそれぞれ格納された変数です。変数に異なる型のデータを割り当てることができるため、Pythonでは柔軟にデータを扱えます。
演習問題
- 自分で変数を3つ作成し、整数、小数、文字列をそれぞれ割り当ててみましょう。
- その後、それぞれの変数を
print()関数で出力してみてください。
リストと辞書
Pythonでは、データを集約して扱うための便利なデータ構造として、リストと辞書があります。リストは、複数の値を順番に並べて保存できるデータ構造で、辞書はキーと値のペアでデータを管理する構造です。
リストの基本操作
# リストの作成
numbers = [1, 2, 3, 4, 5]
# リストの要素にアクセス
print(numbers[0]) # 出力: 1
# リストに新しい要素を追加
numbers.append(6)
print(numbers) # 出力: [1, 2, 3, 4, 5, 6]辞書の基本操作
# 辞書の作成
person = {"name": "Alice", "age": 25, "city": "Tokyo"}
# 辞書の要素にアクセス
print(person["name"]) # 出力: Alice
# 辞書に新しいキーと値を追加
person["job"] = "Engineer"
print(person) # 出力: {'name': 'Alice', 'age': 25, 'city': 'Tokyo', 'job': 'Engineer'}演習問題
- 自分でリストを作成し、リストにいくつかの値を追加してみましょう。
- また、辞書を作成して、その中に「名前」「年齢」「趣味」などの情報を格納してみてください。
関数の定義
関数とは、特定の処理をひとまとめにして、必要なときに呼び出すことができる機能です。これにより、同じ処理を繰り返し書く必要がなくなり、コードを効率的かつシンプルに保つことができます。
関数の基本
# 関数の定義
def greet(name):
return f"Hello, {name}!"
# 関数の呼び出し
print(greet("Alice")) # 出力: Hello, Alice!この例では、greetという関数を定義し、nameという引数を受け取って挨拶のメッセージを返すようにしています。
演習問題
- 自分で関数を定義し、引数を受け取って、その引数に基づいて異なるメッセージを返す関数を作成してみてください。
小さなプログラムを作成してみよう
ここまで学んだ内容を使って、簡単なプログラムを作成してみましょう。リスト、辞書、関数を組み合わせて、自分のプロフィールを管理するプログラムを作ってみてください。
プロフィール管理プログラム
# プロフィールの辞書を作成
profile = {"name": "Alice", "age": 25, "city": "Tokyo"}
# プロフィールを表示する関数
def show_profile(profile):
for key, value in profile.items():
print(f"{key}: {value}")
# プロフィールを更新する関数
def update_profile(profile, key, value):
profile[key] = value
print(f"{key}が{value}に更新されました")
# プロフィールの表示
show_profile(profile)
# 年齢を更新
update_profile(profile, "age", 26)
# 再度プロフィールを表示
show_profile(profile)演習問題
- 上記のプログラムを自分の情報に書き換え、プロフィールを表示してみましょう。
- 新しいキーを追加して、趣味や職業をプロフィールに追加してみてください。
お疲れ様でした。Pythonの基本的な文法、データ型、リスト、辞書、関数の使い方を学ぶことができました。これらは、今後機械学習ファイナンスでデータを処理したり、戦略を実装したりするために非常に重要な基礎です。
NumPyを使った数値データの操作
Pythonで数値データを扱う際、特に大規模なデータセットや高い計算速度が求められる機械学習ファイナンスにおいて、NumPyは非常に強力なライブラリです。NumPyは多次元配列(Array)や行列計算、統計処理を効率的に行うための豊富な機能を提供しており、機械学習ファイナンスにおけるデータ処理の基盤となります。
NumPyのインストール
NumPyはPythonの外部ライブラリであるため、まずはインストールを行います。Anacondaを使っている場合、NumPyはデフォルトでインストールされていますが、そうでない場合は以下のコマンドを実行してインストールしましょう。
pip install numpyインストールが完了したら、NumPyをインポートして使えるか確認します。
import numpy as np配列(Array)の基本操作
NumPyでは、リストと似た形式で「配列(Array)」を扱うことができますが、配列はリストに比べて効率的なデータ操作や計算を可能にします。
NumPy配列の作成と基本操作
import numpy as np
# 配列の作成
prices = np.array([100, 102, 101, 103, 105])
# 配列の要素にアクセス
print(prices[0]) # 出力: 100
# 配列の全要素に対する演算
prices = prices + 1
print(prices) # 出力: [101 103 102 104 106]
# 配列の要素の合計と平均
total = np.sum(prices)
mean = np.mean(prices)
print(f"合計: {total}, 平均: {mean}")この例では、株価データの配列を作成し、全要素に対して一度に演算を行うことができます。また、np.sum()やnp.mean()を使うことで、簡単に合計や平均を計算することができます。
行列計算
NumPyでは、行列を使った計算も非常に簡単に行えます。これは、株価データや複雑なアルゴリズムを実装する際に役立ちます。
行列の作成と基本演算
# 行列の作成
matrix_a = np.array([[1, 2], [3, 4]])
matrix_b = np.array([[5, 6], [7, 8]])
# 行列の加算
matrix_sum = matrix_a + matrix_b
print(matrix_sum)
# 行列の積
matrix_product = np.dot(matrix_a, matrix_b)
print(matrix_product)上記のように、行列の加算や積などの計算を簡単に行うことができます。これらの演算は、株式のポートフォリオ分析や金融モデルでよく使われる数学的計算に応用できます。
株価データを使った統計計算の実例
実際の機械学習ファイナンスでは、株価などの市場データを扱うことが多くなります。ここでは、NumPyを使って、株価データの統計計算を行う簡単な例を紹介します。
株価データの標準偏差と移動平均
# 仮の株価データ
prices = np.array([100, 102, 101, 103, 105, 106, 107, 108, 110])
# 標準偏差の計算
std_dev = np.std(prices)
print(f"標準偏差: {std_dev}")
# 移動平均(3日間)の計算
moving_avg = np.convolve(prices, np.ones(3)/3, mode='valid')
print(f"移動平均: {moving_avg}")このコードでは、np.std()を使って株価の標準偏差を計算し、データのばらつきを確認します。また、np.convolve()を使って3日間の移動平均を計算しています。移動平均は、トレンドを確認するための一般的な手法で、トレーディング戦略の構築に役立ちます。
演習問題
次に、NumPyを使った簡単な演習問題を解いてみましょう。
演習1
以下の株価データを配列に格納し、平均値、合計値、標準偏差を計算してみてください。
prices = [98, 100, 102, 104, 103, 101, 99]演習2
5日間の移動平均を計算し、その結果を出力してください。
# NumPy配列に変換
prices = np.array([98, 100, 102, 104, 103, 101, 99])お疲れ様でした。NumPyを使うことで、数値データの操作や統計計算が簡単に行えるようになります。機械学習ファイナンスにおいて、データを効率的に処理し、正確な計算を素早く行うことは重要な要素です。
Pandasを使ったデータフレーム操作
Pandasは、Pythonを使ったデータ分析において非常に強力なライブラリです。特に、機械学習ファイナンスにおいては、大量のトレーディングデータを効率的に扱うためにPandasを使うことが不可欠です。Pandasを使えば、簡単にデータを読み込み、処理し、分析することができるため、トレード戦略の実装に必要なスキルとなります。
Pandasのインストール
まず、Pandasがインストールされていない場合は、以下のコマンドでインストールします。
pip install pandasインストールが完了したら、Pandasをインポートして使えるようにします。
import pandas as pdCSVファイルの読み込みと表示
トレーディングデータは通常、CSV形式で保存されています。Pandasを使えば、CSVファイルからデータを簡単に読み込み、データフレームとして扱うことができます。
CSVファイルの読み込みと基本的な表示
import pandas as pd
# CSVファイルの読み込み
df = pd.read_csv('stock_data.csv')
# データの最初の5行を表示
print(df.head())
# データの概要を表示
print(df.info())このコードでは、pd.read_csv()を使ってCSVファイルを読み込み、head()メソッドで最初の5行を表示しています。また、info()を使うことで、データの概要(カラム名、データ型、欠損値の有無など)を確認できます。これにより、データの構造を把握しやすくなります。
データフレームの基本操作
Pandasのデータフレームは、Excelの表のような形式でデータを扱います。データをフィルタリングしたり、集計したりする操作も非常に簡単です。
フィルタリングと列の選択
# 特定の列のみ選択
closing_prices = df['Close']
print(closing_prices.head())
# 条件に基づくフィルタリング(価格が100以上の行のみ取得)
filtered_df = df[df['Close'] >= 100]
print(filtered_df.head())この例では、df['Close']で「終値」列のみを抽出し、df[df['Close'] >= 100]で「終値が100以上」の行のみをフィルタリングしています。フィルタリングは、データ分析やトレード戦略に役立つデータを抽出する際に非常に便利です。
データの集計と分析
Pandasを使えば、データの集計や統計的な分析も容易に行うことができます。
データの集計と基本的な統計量の計算
# 全体の統計情報を取得
print(df.describe())
# 特定列の集計(終値の平均と最大値を計算)
mean_close = df['Close'].mean()
max_close = df['Close'].max()
print(f"平均終値: {mean_close}, 最高終値: {max_close}")describe()メソッドを使うと、数値データの基本的な統計量(平均、標準偏差、最小値、最大値など)を一度に取得できます。また、mean()やmax()を使えば、特定の列の平均値や最大値なども簡単に計算できます。
実例:Yahoo Financeの株価データを使った分析
次に、Yahoo Financeから取得した実際の株価データを使って、基本的なデータ操作を行ってみます。Pythonには、yfinanceというライブラリがあり、これを使えば簡単にYahoo Financeからデータを取得できます。
まず、yfinanceライブラリをインストールします。
pip install yfinance次に、実際にデータを取得して分析します。
import yfinance as yf
# 株価データの取得(例: Apple)
df = yf.download('AAPL', start='2022-01-01', end='2022-12-31')
# データの最初の5行を表示
print(df.head())
# 2022年の終値の平均を計算
mean_close = df['Close'].mean()
print(f"2022年の平均終値: {mean_close}")このコードでは、Yahoo FinanceからAppleの2022年の株価データを取得し、終値の平均を計算しています。実際のトレーディングデータを使った分析ができるようになれば、機械学習ファイナンスに必要なデータ処理スキルが自然と身につきます。
演習問題
次に、Pandasを使った簡単な演習を行ってみましょう。
演習1
以下のCSVファイルを読み込み、終値の平均値を計算してください。
# CSVファイルを読み込んで、終値の平均を計算
df = pd.read_csv('your_stock_data.csv')
mean_close = df['Close'].mean()
print(f"平均終値: {mean_close}")演習2
Yahoo FinanceからGoogleの株価データを取得し、終値の最大値と最小値を計算してください。
# Googleの株価データを取得し、終値の最大値と最小値を計算
df = yf.download('GOOGL', start='2022-01-01', end='2022-12-31')
max_close = df['Close'].max()
min_close = df['Close'].min()
print(f"最高終値: {max_close}, 最低終値: {min_close}")お疲れ様でした。Pandasを使うことで、トレーディングデータを効率的に読み込み、分析することができます。データフレームの操作をマスターすれば、機械学習ファイナンスの戦略を実装する際のデータ処理がスムーズに行えます。次回は、これらのデータを使ったトレーディング戦略の実装に進みます。
機械学習に必要なライブラリの紹介
機械学習ファイナンスで機械学習やディープラーニングを活用するには、いくつかの主要なライブラリがあります。これまで紹介した scikit-learn、TensorFlow、Keras に加えて、ここでは PyTorch も紹介します。PyTorchは、特にカスタマイズ性や動的計算グラフを利用したモデル開発に強みがあります。
scikit-learn:ベーシックな機械学習アルゴリズム
scikit-learn は、ベーシックな機械学習アルゴリズムを簡単に使えるライブラリです。分類、回帰、クラスタリングなどの基本的なアルゴリズムが豊富に揃っています。
用途と特徴
- 教師あり・教師なし学習の基本アルゴリズムがサポートされている。
- 特に、価格予測や市場トレンド分析など、基本的な予測モデルの構築に適している。
インストール
pip install scikit-learnTensorFlow:ディープラーニング用ライブラリ
TensorFlow は、Googleによって開発されたディープラーニングフレームワークです。大量のデータを使った予測や最適化に適しており、GPUを活用した高速なモデルトレーニングが可能です。
用途と特徴
- 深層学習モデルを使った高度な予測ができる。
- 時系列データに基づく機械学習ファイナンス戦略の最適化に向いている。
インストール
pip install tensorflowKeras:シンプルなディープラーニングフレームワーク
Keras は、TensorFlowの上に構築されており、シンプルなAPIを提供しています。複雑なニューラルネットワークを簡単に構築できるため、ディープラーニングの初心者にも適しています。
用途と特徴
- TensorFlowベースで、手軽にモデルを構築。
- 簡単な構文で複雑なモデルのプロトタイプを作成できる。
インストール
pip install kerasPyTorch:柔軟でカスタマイズ可能なディープラーニングライブラリ
PyTorch は、Facebookが開発したオープンソースのディープラーニングライブラリです。動的計算グラフを使った柔軟なモデル構築が特徴で、特にリサーチやプロトタイピングにおいて広く使われています。PyTorchは、自由度が高いため、カスタムなモデルや特殊なアルゴリズムを必要とするトレーディングシステムの開発に向いています。
用途と特徴
- 動的計算グラフを使った柔軟なモデル構築が可能。
- TensorFlowよりも直感的なAPIを提供し、特に研究者や実験的プロジェクトに人気。
- LSTMや強化学習モデルの開発に適しており、複雑な機械学習ファイナンス戦略を設計するのに最適。
インストール
pip install torchPyTorchでの簡単なモデル構築例
import torch
import torch.nn as nn
# シンプルなニューラルネットワークモデル
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(10, 50)
self.fc2 = nn.Linear(50, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
return self.fc2(x)
# モデルのインスタンス化
model = SimpleModel()お疲れ様でした。各ライブラリには、それぞれの強みがあります。scikit-learnは基本的な機械学習に適しており、TensorFlowやKerasはディープラーニングに強力なサポートを提供します。さらに、PyTorchは柔軟でカスタマイズ性が高く、より高度な機械学習ファイナンス戦略の実装に向いています。これらのツールを適切に使い分けることで、機械学習ファイナンスの性能を最大化することができます。
まとめと次回予告
今回のブログでは、機械学習ファイナンスを始めるための最初のステップとして、Python環境の設定から基本的なデータ処理までを学びました。AnacondaやJupyter Notebookのセットアップを行い、NumPyやPandasを用いた数値データの扱い方に触れました。また、機械学習の基礎となるライブラリの紹介も行い、機械学習ファイナンスを実践するための基盤を整える準備ができました。これらの知識をしっかりと身につけることで、今後のトレーディング戦略の構築に役立てていくことができます。
次回は、機械学習ファイナンスとは何か?というテーマで、機械学習ファイナンスの概要を掘り下げて解説します。機械学習ファイナンスがどのようにして市場で活用されているのか、そしてAIや機械学習がどのような役割を果たしているのかを学びます。また、金融市場の仕組みや、代表的なトレーディング手法、そしてリスク管理の重要性についても詳しく解説します。
次回も、理論と実践をバランスよく取り入れ、機械学習ファイナンスの理解をさらに深めていきますので、ぜひお楽しみに!


コメント