Fine-tuningとは?
ファインチューニングは、大量のデータで事前に学習されたモデルを特定のタスクやデータセットに合わせて微調整するプロセスです。わかりやすく説明すると大規模言語モデルが大きすぎて対応できない場合や、大規模言語モデルの情報が足りない場合などに有効です。
Fine-tuningの効果
- Few-shot Promptingによるプロンプトの工夫により、特定の問題領域におけるより細かいパターンやニュアンスを学習することができる。
- 特定のタスクや新しいタスクに対してより正確な予測や分析を行うことが可能になる。
- 既存のデータ以上の情報を肉付けするため、実際のアプリケーションやサービスでの有用性が向上する。
- プロンプトに収まりきらないほどの多くの例を学習することができる。
Fine-tuningが有効な具体的な場面
ファインチューニングは大規模なデータセットで事前に訓練されたモデルを、特定のニーズや要件に合わせて微調整するプロセスであるが、ファインチューニングが最も有効な場面についての例を挙げてみます。
医療画像解析
医療分野では、患者の個人情報や機密性の高いデータが含まれるため、大規模な公開データセットが限られているが、ファインチューニングを用いることで、限られた医療画像データを活用して、特定の疾患の検出や診断のためのモデルを最適化することが可能です。たとえば、X線画像やMRI画像を使用して、肺がんの検出や脳卒中の予測に焦点を当てることができます。
金融市場取引
金融市場取引におけるファインチューニングは、限られたデータセットを活用し、特定の市場の特異性や時系列データのパターンをより正確に捉えるための効果的な手法です。特に、金融市場の動向予測や取引戦略の最適化において、ファインチューニングされたモデルは高い性能を発揮します。
特定の言語コーパスの作成
特定の地域や文化圏で使用される言語に関する翻訳モデルを構築する場合、限られた言語データを使用してファインチューニングを行うことで、そのモデルの性能を向上させることができます。
小規模なビジネスのデータ分析
小規模なビジネスやスタートアップ企業は大規模なデータセットを容易に活用できなかったり、実用的でないことがありますが、自社の顧客データや売上データなど限られたデータを使用して、需要予測や顧客セグメンテーションなどのタスクにファインチューニングを適用することで、効果的なモデルを構築することができます。
Fine-tuningのユースケース
- 目的に応じた出力の信頼性の向上
- 複雑なプロンプトに応じた修正が必要なケース
- 文体や口調などを考慮に入れる場合
- コストや時間を節約したい場合
Fine-tunigを使ってみる
Fine-tuningの利用料金
Fine-tuningはテキスト生成や画像生成、埋め込みと同様に利用料金がかかります。

Fine-tuningが可能なモデル
- gpt-3.5-turbo-1106(推奨モデル)
- gpt-3.5-turbo-0613
- babbage-002
- davinci-002
Fine-tuningすべきかどうか?
- プロンプトを考慮することによりFine-tuningの必要がない場合がある。
- Fine-tuningは時間もコストもかかるために本当に必要であるかどうかを検討する必要がある。
- Fine-tuningが必要な場合でも最適なプロンプトを使用する方がより良い結果を得ることができるため、まずはFine-tuningを行う前に最適なプロンプトを考えてみるべきである。
Fine-tuningの手順
- データセットの準備
- トレーニングファイルをアップロードする
- Fine-tuningを実行する
- Fine-tuningしたモデルを使用する
データセットを準備する
以下はOpenAIのチャットボットのトレーニングデータのサンプルです。

{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}同様にサンプルデータセットを用意します。今回は「つくよみちゃん会話AI育成計画」の会話データセットを取得したのでこれを使って説明します。

とりあえず「Excel形式でダウンロード」をクリックしてデータをダウンロードしてください。その後、ExcelファイルをCSVファイルに変換して保存してください。
トレーニングファイルをアップロードする
環境準備
今回もGoogleColaboratoryを使って説明しようと思います。まずはいつも通り、OpenAIのAPIキーを取得し、必要なライブラリをインポートします。APIキーの取得は下記を参考にしてみてください。

!pip install openai
# 環境変数の準備
import os
os.environ["OPENAI_API_KEY"] = "<OpenAIキーを入力>"Colabの左にCSVファイルをアップロードしてください。
次にCSVファイルをJsonlファイルにファイル変換します。ファイル変換後はColabの左側に「tsukuyomi.jsonl」というファイルが表示されます。
import pandas as pd
# データセットの準備
df = pd.read_csv(
'tsukuyomi.csv',
usecols=[1,2],
names=['prompt','completion'],
skiprows=2)
df.to_json(
"tsukuyomi.jsonl",
orient='records',
lines=True,
force_ascii=False
)「tsukuyomi.jsonl」ファイルは以下のような形式で出力されます。
{"prompt":"お腹が鳴る","completion":"何か召し上がりますか?"}
{"prompt":"だるい","completion":"それは心配です。私にできることがあれば、何でもお申し付けください。"}
{"prompt":"眠れない","completion":"何も心配する必要はありません。私がついています。ずっと、ずっと、一緒です。"}今回使用するモデルである、gpt-3.5-turbo-0613は更に別のファイル形式に変更してあげる必要があるため、もう一度ファイルの変換を行います。
import json
# 元のJSONLファイルを開きます
with open('/content/tsukuyomi.jsonl', 'r', encoding='utf-8') as f:
data = [json.loads(line) for line in f]
# 新しい形式のデータを作成します
new_data = []
for item in data:
new_item = {
"messages": [
{"role": "system", "content": "「つくよみちゃん」という名前のチャットボットです。"},
{"role": "user", "content": item["prompt"]},
{"role": "assistant", "content": item["completion"]}
]
}
new_data.append(new_item)
# 新しい形式のデータを新しいJSONLファイルに書き込みます
with open('tsukuyomi_2.jsonl', 'w', encoding='utf-8') as f:
for item in new_data:
f.write(json.dumps(item, ensure_ascii=False) + '\n')ファイルの変更が行われるとColabの左側に「tsukuyomi_2.jsonl」というファイルが作られます。
{"messages": [{"role": "system", "content": "「つくよみちゃん」という名前のチャットボットです。"}, {"role": "user", "content": "お腹が鳴る"}, {"role": "assistant", "content": "何か召し上がりますか?"}]}
{"messages": [{"role": "system", "content": "「つくよみちゃん」という名前のチャットボットです。"}, {"role": "user", "content": "だるい"}, {"role": "assistant", "content": "それは心配です。私にできることがあれば、何でもお申し付けください。"}]}
{"messages": [{"role": "system", "content": "「つくよみちゃん」という名前のチャットボットです。"}, {"role": "user", "content": "眠れない"}, {"role": "assistant", "content": "何も心配する必要はありません。私がついています。ずっと、ずっと、一緒です。"}]}これで、gpt-3.5-turbo-0613を使ってFine-tuningを行う準備が整いましたので変更した「tsukuyomi_2.jsonl」ファイルを以下のファイルにアップロードします。
from openai import OpenAI
client = OpenAI()
client.files.create(
file=open("tsukuyomi_2.jsonl", "rb"),
purpose="fine-tune"
)実行後に以下のようなファイルIDが記載されますのでコピーして次のコードに貼り付けてください。
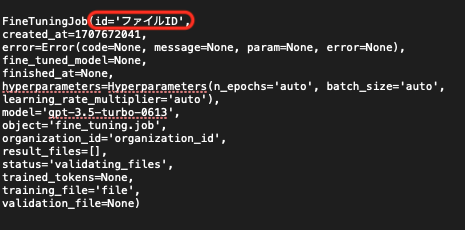
Fine-tuningを実行する
次に上記でコピーしたファイルIDをtraning_fileにペーストしてください。
from openai import OpenAI
client = OpenAI()
client.fine_tuning.jobs.create(
training_file="上記のファイルIDを入力",
model="gpt-3.5-turbo"
)Fine-tuningは完了するまでに時間を要します。完了するとユーザーにOpenAIから確認メールが届きますので必ず確認してください。
Fine-tuningのジョブリストの表示、状態の表示、キャンセル、リスト表示、モデルの削除なども行うことができます。
import openai
# ファインチューニングのジョブのリスト表示
openai.FineTuningJob.list(limit=10)
# ファインチューニングのジョブの状態表示
openai.FineTuningJob.retrieve("ft-abc123")
# ファインチューニングのジョブのキャンセル
openai.FineTuningJob.cancel("ft-abc123")
# ファインチューニングのジョブのイベントのリスト表示
openai.FineTuningJob.list_events(id="ft-abc123", limit=10)
# ファインチューニングしたモデルの削除
openai.Model.delete("ft-abc123")Fine-tuningしたモデルを使用する
OpenAIからのメールが届いたらモデル名をコピーして下記のコードにペーストしてください。

from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="メールに届いたモデル名を入力",
messages=[
{"role": "user", "content": "好きな食べ物は何?"}
]
)
print(response.choices[0].message.content)コードを実行すると無事「絵に描いた餅です!」という回答が得られました。これはつくよみちゃんならではのセリフですので学習できていることがわかります。
ちなみに「絵に描いた餅」とは何かを調べてみたところ、どんなに巧みに描いてあっても食べられないことから「何の役にも立たないもの」、「実物・本物でなければ何の値打ちもないこと」などを指します。
まとめ
OpenAIのAPIを利用したFine-tuningは、特別な設備不要で始められ、時間とコストを節約しながら最先端のAI技術をカスタマイズできます。
おまけ / 研究コーナー
ChatGPT PlusのDALL-E 3
OpenAIのDALL-E 3の可能性を見出すべく、ChatGPT PlusのDALL-E 3を使って生成画像を作る上で有効的なプロンプトを生成してみたいと思います。
プロンプトの役割・条件・キーワード
あなたは世界的に有名な画家で趣味は写真を撮ることです。最近は描いてきた絵の見識美を活かして小説も書き始めました。 下記の条件を踏まえながら、条件とキーワードを踏まえてDALL-E3を使った画像生成に有効なプロンプトを作ってください。 ・表現手法 ・色彩 ・画像のイメージ(モノクロ、アニメ風など) ・Fine-tuning ・coding ・黄金螺旋
生成された画像
今回はプロンプトを作る前に画像を生成したこともあり、プロンプトは生成されませんでした。

画像の補足説明
表現手法
複雑で詳細なデジタルアート技法が使用されており、抽象的なコーディング要素が黄金螺旋の形に緻密に統合されています。
色彩
豊かで鮮やかなカラーパレットが使用されており、金、青、緑などの色が特に際立っています。
画像のイメージ
テクノロジーと自然の美が調和した、高度な精度とエレガントなデザインが特徴のイメージです。
まとめ
このプロンプトを使用することで、DALL-E 3は、「コードの螺旋」を表現した画像を生成することができたと言えます。


コメント